
Introducing DuckDB - Fast and Simple Data Processing with CLI and Python
Set you up running with duckdb in the cli and Python

DuckDB is great. It’s a fast analytical database or data processing tool using SQL. Its speed and feature-rich SQL dialect have already attracted many data professionals. People say it’s “SQLite for analytics“. You may already have heard of DuckDB or played with it before. Don’t confuse DuckDB with OLTP (Online Transaction Processing) databases. DuckDB is an OLAP (Online Analytics Processing).
In this article, I’ll introduce how to use DuckDB from the CLI and in Python. These are two straightforward and accessible approaches that many people are already familiar with.
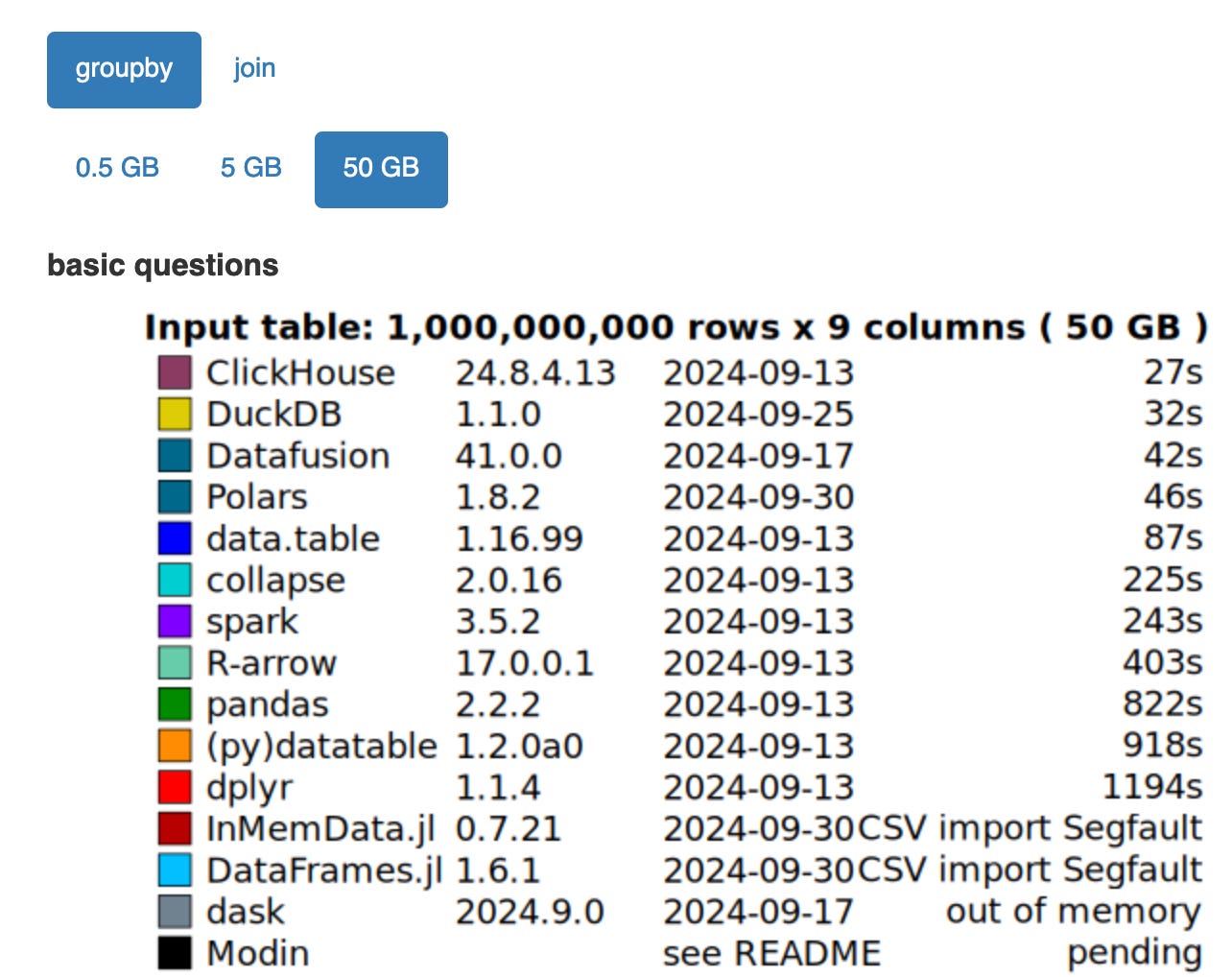
It might be worth noting that I won’t compare DuckDB's performance with other tools like Polars in this article (though I may have a screenshot of a benchmark) - that’s a topic for another discussion.
Here are some things I’ll go over in this article:
Why You Should Use DuckDB
DuckDB installation
Using DuckDB from the CLI
Using DuckDB in Python
How People Use DuckDB in Production
Limitations
Why Use DuckDB?
A picture is worth a thousand words. I took the following screenshot from DuckDB’s website:

The 3 things that matter most to me are:
Simple
Feature-rich
Fast
DuckDB is simple. It’s easy to install anywhere and start leveraging its analytical capability. You can install DuckDB through Homebrew. In Python, it’s just a pip install away.
DuckDB is feature-rich. Its SQL dialect allows you to work with data in many forms like CSV, Parquet, and JSON. You can easily work with files in your local machine or files in your S3 bucket (or a remote filesystem in the cloud).
DuckDB is fast. While no benchmark is entirely unbiased, they still give us an idea of how something might perform in practice. If you’ve encountered their benchmark, you can see how fast DuckDB is to process large datasets. Are you a Polars fan? DuckDB is as fast if not faster.
Using DuckDB From the Command Line
It’s only one command away from using DuckDB from the CLI (Command Line Interface).
Install the DuckDB CLI
I use a Mac so I install DuckDB through Homebrew:
brew install duckdbIf you’re using some other OS like Windows or Linux, please refer to DuckDB’s documentation.
After the installation, you can check the DuckDB version:

Start Working in an Interactive Interface
How do you start working from the CLI? Just type this in your terminal:
duckdbThis will open a temporary in-memory database in an interactive interface where you can freely write and execute your SQL queries in DuckDB. It even tells you that you are connected to an in-memory database:

Let’s type in some SQL commands:
select 1;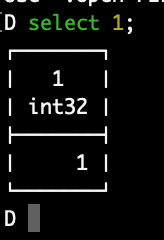
create table if not exists my_table as select 100;
select * from my_table;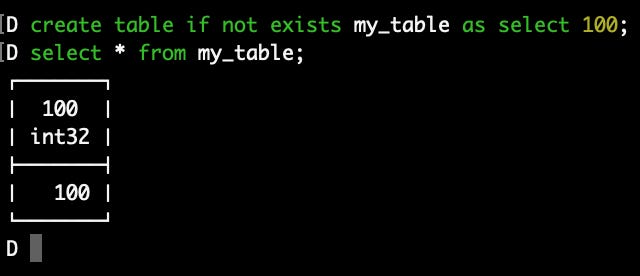
Now, we’re using a temporary in-memory database, meaning once you exit the session, you’ll lose your work (you can exit the session with the shortcut of “Ctrl + D” or type “.exit“). If you want to persist your data in a DuckDB database, then add a file name when you open a database like this:
duckdb my_duckdb_db.dbBy doing so, you’re telling DuckDB that you’re working with that specific database file. If you create tables, schemas, etc then they will be persisted in that database file.
There are optional arguments specific to working with the DuckDB CLI. If you’re interested in learning more about that, please visit the DuckDB documentation page.
Working With a CSV and Parquet File
Now, let’s try reading from a file and writing data to a file.
Create a CSV file, I use Vim for this, but use whatever code editor you’d like:
vi sample_data.csvcol_a,col_b
1,'a'
2,'b'
3,'c'Let’s open and connect to a persistent database:
duckdb my_db.dbAnd read the CSV file in DuckDB:
select * from read_csv('sample_data.csv');
Now, let’s convert this to Parquet and read it in DuckDB again:
copy (select * from read_csv('sample_data.csv')) to 'sample_data.parquet' (format 'parquet');select * from read_parquet('sample_data.parquet');
When you write to a file, you utilize DuckDB’s COPY command.
So, if you want to persist a table from a file, you can do a SQL query like this:
create table if not exists sample_table as select * from read_parquet('sample_data.parquet');select * from sample_table;
As you can see, you can connect and start working with DuckDB so quickly!
Working With Files in S3
For DuckDB to work with files in a remote file storage like S3, you’ll need to install an extension. In our case, we’ll install the `httpfs` extension. Let’s execute a few commands.
INSTALL httpfs;
LOAD httpfs;Set up credentials to read data:
CREATE SECRET (
TYPE S3,
KEY_ID 'YOUR_KEY_ID',
SECRET 'YOUR_SECRET',
REGION 'YOUR_REGION'
);
In my S3 bucket, I have the same sample_data.parquet file:

Let’s read it into DuckDB. The only thing you need is the S3 file URI:
select * from read_parquet('s3://sandbox-data-lake/sample_data.parquet');
You can use the copy command to write to S3 as well:
copy (select 1) to 's3://sandbox-data-lake/sample_data.csv' (format 'csv');Now I see the new file added to my S3 bucket:
Do you see how easy it is to set up an S3 connection and start working with your files in S3? This is the power of simplicity that DuckDB provides you to improve your workflow. To learn more about working with cloud storage in DuckDB, please check out their documentation page.
Using DuckDB with Python
Alright, let’s shift gears to Python. For this one, I have a GitHub repo I store all my code in.
Set up the Python Environment
uv venv
uv pip install duckdb
The overall workflow doesn’t change compared to working with the CLI. For instance, you’ll simply use .sql to execute your SQL queries:
import duckdb
print(duckdb.sql('select 1;'))
For reading data from files, you can insert the kind of SQL queries we used with the CLI in the .sql function, or use dedicated functions like .read_parquet.
Reading and Writing Files
Read a parquet file in a local file system:
# read files
duckdb_relation = duckdb.sql('select * from read_parquet("data/sample_data.parquet")')
print(duckdb_relation)
# or
duckdb_relation = duckdb.read_parquet('data/sample_data.parquet')
print(duckdb_relation)
To write to a parquet file:
# write files
duckdb.sql('copy (select 1 as col_a) to "data/sample_data.csv" (format csv)')
# or
duckdb.sql('select 1 as col_a').write_parquet('data/sample_data.csv')Let’s read from and write to S3:
# working with s3
# 'rel' as in duckdb relation
# read
duckdb.sql(f'''
install httpfs;
load httpfs;
CREATE SECRET (
TYPE S3,
KEY_ID 'YOUR_KEY_ID',
SECRET 'YOUR_SECRET',
REGION 'YOUR_REGION'
);
''')
rel = duckdb.sql('select * from read_parquet("s3://sandbox-data-lake/sample_data.parquet");')
print(rel)
# write
rel.write_parquet("s3://sandbox-data-lake/sample_data.parquet")
If you want to connect to a persistent database, you can use something like this. You’ll just use functions off on con, your connection instance:
con = duckdb.connect("~/my_db.db")
print(con.sql('show all tables;'))
Bonus - Running DuckDB SQL on a DataFrame
Yes, you read that right. You can run DuckDB SQL directly on a dataframe, like pandas dataframe and Polars dataframe. Since Polars’ SQL interface isn’t as feature-rich as DuckDB’s, this integration is a great enhancement. This integration requires pyarrow to be installed.
# running duckdb sql on a polars dataframe
import polars as pl
df = pl.DataFrame({'a': [1,2,3]})
print(duckdb.sql('select * from df;'))
To go deeper into using DuckDB in Python, you can visit this documentation page.
How Are People Using DuckDB in Production?
Okay, now we know it’s easy to do some quick data tasks from the CLI and Python, but is DuckDB used in production anywhere? The answer is yes.
One famous use case is that Mode, a BI tool, switched its in-memory engine to DuckDB. I guess you can also say MotherDuck is DuckDB for analytics in the cloud.
Other ones I can think of are dbt-duckdb and SQLMesh. dbt-duckdb is a dbt plugin that allows you to use DuckDB as dbt’s execution engine for reading from and writing to remote file storage like S3. SQLMesh uses DuckDB as its test connection by default. You can also use it as its execution engine locally.
Also, as we saw in this article about how easy it is to develop data processing pipelines with DuckDB in Python, you can imagine hosting data ingestion/transformation pipelines in serverless functions or an orchestration tool like Airflow.
DuckDB surely brings a lot of potential to improve our data workflows.
Limitations
A big limitation of DuckDB is the lack of write support for Delta Lake and Iceberg. Sure, DuckDB can read from these formats, but typically the native write support is what makes a difference. Polars also lacks write support for Iceberg, but it has read and write support for Delta.
Conclusion
All in all, DuckDB is an awesome tool and great for quick data analysis or processing tasks on your laptop. It’s easy to set up and get started with, it’s super fast, and uses what people are most familiar with, SQL.
I hope that through this article, you found how useful DuckDB might be in your workflow!