
Meet FireDucks: The Ultra-Fast Drop-In Replacement for Pandas
Speed up your pandas workflows without changing your code

This article is delivered in partnership with the FireDucks Development Team at NEC’s R&D department.
Have you heard of FireDucks? I hadn’t until I saw this benchmark shared on LinkedIn sometime last year (2024):
When I saw this, I was like, “No way it’s that fast. It’s as fast as Polars!“. And that’s the moment I decided to learn more about FireDucks.
This article serves as a comprehensive introduction to FireDucks. It focuses on explaining what FireDucks is, what it offers, and how you can start using it today. By the end, you'll have enough information to decide whether it's worth exploring further.
Here are section titles in this article:
What is FireDucks?
Why FireDucks Matters
Key Differences Between FireDucks and Pandas
FireDucks Performance Benchmarks
FireDucks in Action: A Quick Look
Who Should Consider Using FireDucks?
Limitations
Conclusion
What is FireDucks?

Let’s see what the website says about the definition of FireDucks:
Compiler Accelerated DataFrame Library for Python with fully-compatible pandas API
( https://fireducks-dev.github.io/)
Okay, let me rephrase that in my own terms:
FireDucks is an ultra-fast drop-in replacement for pandas.
To elaborate a bit more, FireDucks helps accelerate your pandas code without requiring any changes to the code itself. This is somewhat similar to cuDF, which provides a Pandas-like API. However, while cuDF leverages GPU acceleration, FireDucks primarily operates on the CPU (The GPU version of FireDucks is in development).
Why FireDucks Matters
We all know the usefulness and wide adoption of pandas in the data community. Whether it's building data science workflows, prediction models, or data processing pipelines, pandas has long been the go-to tool. However, it's also well-known that pandas struggles with handling larger datasets efficiently.
As data sizes expand and performance costs rise, the need for high-performance DataFrame libraries grows. There are existing high performing DataFrame libraries such as Polars, Daft, Ibis, DuckDB, etc, however, these libraries typically require users to adopt entirely new APIs, leading to migration costs, while some necessitate more powerful hardware, increasing infrastructure expenses.
And this is where FireDucks comes in. Since it’s fully compatible with the pandas API, it can boost the performance of your code without changing anything in your infrastructure and code. It just makes your pandas code much more efficient with much less work.
Additionally, as large language models (LLMs) increasingly play a significant role in the data space, the fact that FireDucks uses the same pandas API gives users an advantage. It allows them to leverage LLMs more effectively, compared to other tools that LLMs may have limited knowledge of, to build and optimize their code.
Key Differences Between FireDucks and Pandas
There are a few key differences worth noting between FireDucks and pandas. We’ll go over these FireDucks’ features in this section:
Execution Model
Performance Accelerator
FireDucks’ Own API
Execution Model
Pandas uses an eager execution model, while FireDucks uses a lazy execution model. With eager execution, the query is evaluated immediately, line by line. In contrast, lazy execution delays the query execution until the result is actually needed, allowing FireDucks more flexibility to optimize and run the query more efficiently.
Lazy execution is also used in other libraries such as Spark, Polars, DuckDB. Employing a lazy execution model is a must for building high-performing data workflows.
Performance Accelerator
There are 2 mechanisms that are key to FireDucks’s high performance.
Compiler Optimization
FireDucks utilizes a runtime compilation mechanism to translate Python code into an intermediate language before execution. Instead of running the Python code directly, it refines the underlying instructions, effectively automating the optimizations that a developer would need to apply manually.
Here is an optimization example: let’s say you have the following code where you filter your data on the column
a, and selects the columnb:selected = df[df["a"] > 10]["b"]This code is not as efficient as it could be. It selects all columns first and then chooses the one to return, whereas it would be more efficient to select only the necessary columns before applying filtering. FireDucks recognizes this inefficiency and optimizes the process by extracting only the required columns first. The optimized code would look something like this:
tmp = df[["a", "b"]] selected = tmp[df["a"] > 10]["b"]
Multi-threading
FireDucks includes a multi-threaded backend, which is based on Apache Arrow.
Although it is backed by Apache Arrow data structures, FireDucks implements most of the operations (like join, group by, sort, etc) with its own efficient parallelization.
FireDucks’ Own API
Firstly, FireDucks gives you methods like to_pandas and from_pandas to help with conversion to and from pandas. Obviously, these don’t exist in the pandas API, and is unique to FireDucks’ API.
import fireducks.pandas as pd
# export to pandas dataframe
pandas_df = fireducks_df.to_pandas()
# import from pandas dataframe
fireducks_df = pd.from_pandas()Secondly, FireDucks offers a way to force the accumulated operators to be executed at a given point, through the _evaluate DataFrame method. This is particularly useful for debugging at certain stages of a query or measuring execution time up to that call.
Perhaps, if you had the code that:
Reads data from a CSV file
Fills missing values
Sorts the DataFrame
And you want to measure the performance of reading a CSV file specifically, you can use the _evaluate method like this:
df = pd.read_csv("CSV_FILE_PATH")._evaluate()You can also force FireDucks to use an eager execution model, which is that you modify the value of the FIREDUCKS_FLAGS environment variable like the following:
import os
os.environ['FIREDUCKS_FLAGS']="--benchmark-mode"
# or through fireducks options
from fireducks.core import get_fireducks_options
get_fireducks_options().set_benchmark_mode(True)Enabling benchmark mode essentially makes your FireDucks code behave like pandas, with no optimizations applied.
Finally, FireDucks provides an API for feature generation. This is especially useful in machine learning use cases.
FireDucks Performance Benchmarks
Let's take a look at a few benchmarks comparing FireDucks' performance to that of other libraries. A picture is worth a thousand words. I hope these will tell you the kind of performance boost you could expect from implementing FireDucks in your existing pandas workflows.
TPC-H benchmark
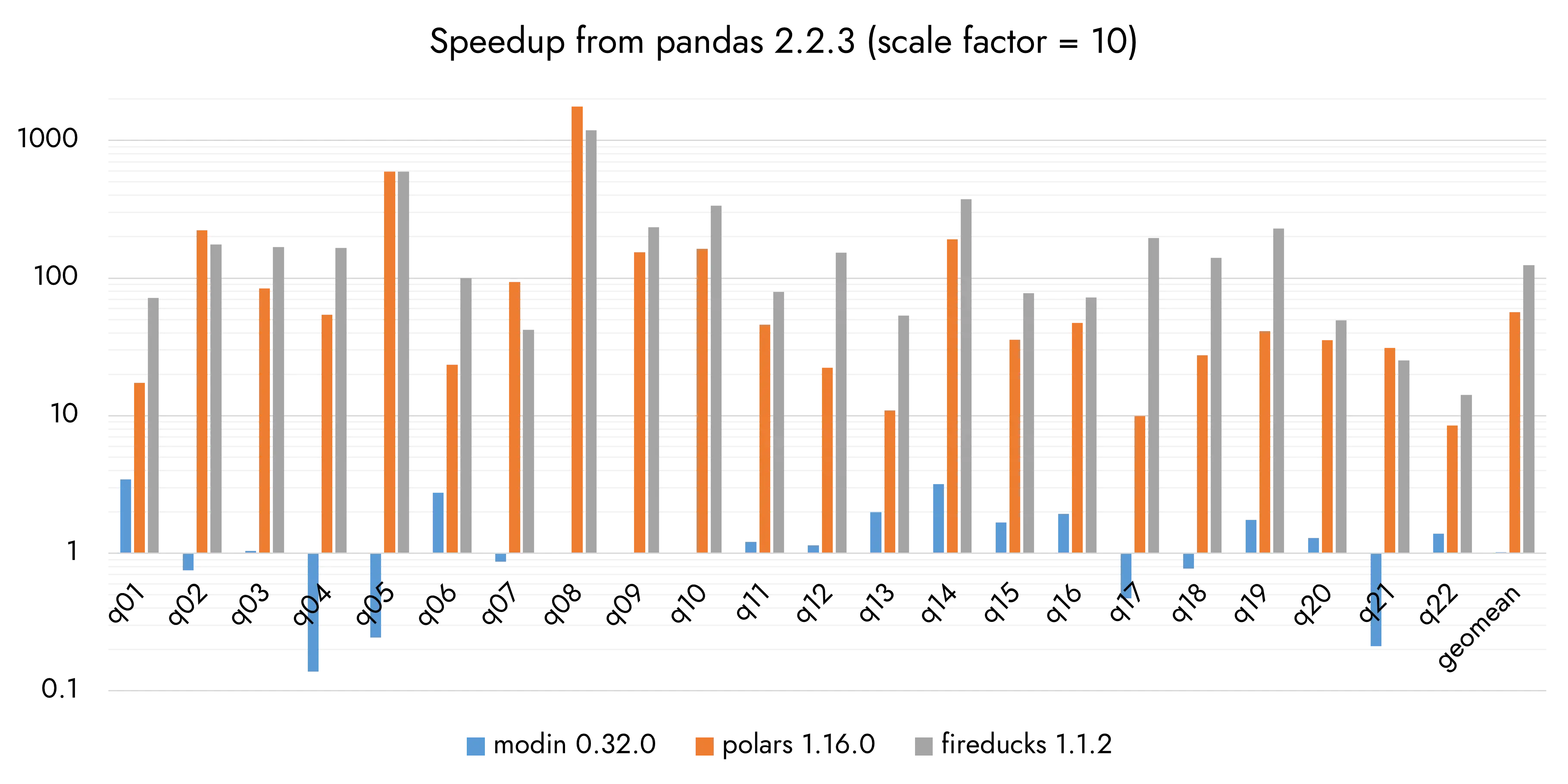
I shared a screenshot of this benchmark at the beginning of the article, but a newer version is available, so let’s review that one instead. This updated version compares pandas, FireDucks, DuckDB, and Polars (replacing Modin with DuckDB). It also includes evaluations both with and without I/O.
Here’s how to read the visualization (I know I got confused at first, too):
The y-axis is NOT in seconds, it’s on a logarithmic scale. Whatever took for pandas is at “1” on the y-axis and bars are basing off pandas’ performance.
The longer the bar, the more performant compared to pandas
You saw in the older benchmark, that some queries for Modin fall below “1”, meaning they perform worse or take longer to process than in pandas.
Server specs:
AWS EC2 m7i.8xlarge
CPU: Intel(R) Xeon(R) Gold 6526Y (32cores)
Main memory: 512 GB
Library Versions:
pandas: 2.2.3
DuckDB: 1.1.3
Polars: 1.21.0
FireDucks: 1.2.0
Excluding I/O:

Including I/O:

According to this benchmark, for 22 queries, on average:
Excluding I/O:
FireDucks performed 79x over pandas
Polars performed 39x over pandas
DuckDB performed 63x over pandas
Including I/O:
FireDucks performed 38x over pandas
Polars performed 32x over pandas
DuckDB performed 43x over pandas
FireDucks outperforms both Polars and DuckDB in the benchmark excluding I/O. However, in the benchmark including I/O, FireDucks falls behind DuckDB but still outperforms Polars.
This is impressive. All these three libraries are blazingly fast, but FireDucks definitely stands out in this benchmark.
Database-like ops benchmark
I’m going to look at queries on a 50 GB dataset. I’m not too concerned with benchmarks on a 5 GB dataset since FireDucks is meant for larger-scale use.
Server specification (conforms to db-benchmark measurement conditions):
CPU model: Intel(R) Xeon(R) Platinum 8375C CPU @ 2.90GHz
CPU cores: 128
RAM model: NVMe SSD
Main memory: 256gb
Queries on basic questions:
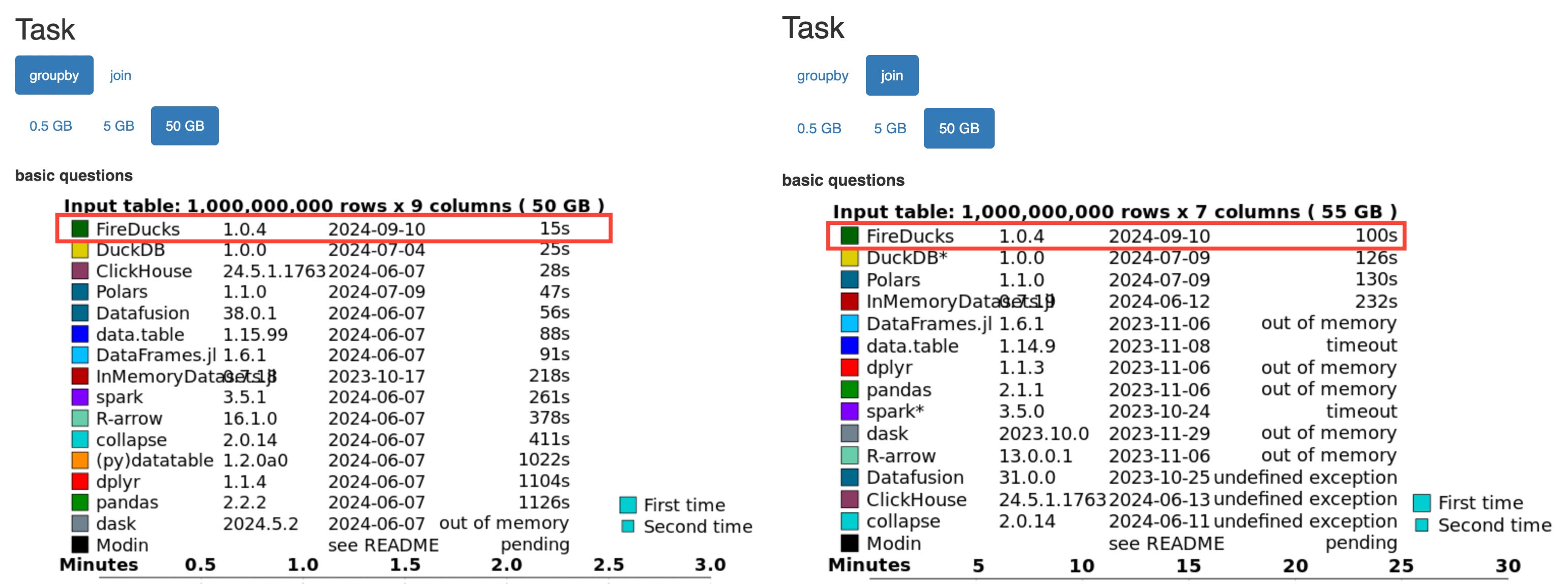
Let’s compare the performance of FireDucks with that of DuckDB and Polars.
Group by operations:
FireDucks: 15 seconds
DuckDB: 25 seconds
Polars: 47 seconds
Join operations
FireDucks: 100 seconds
DuckDB: 126 seconds
Polars: 130 seconds
FireDucks beat both DuckDB and Polars!
Now we look at the queries on advanced questions, which are only available for the group by operations:
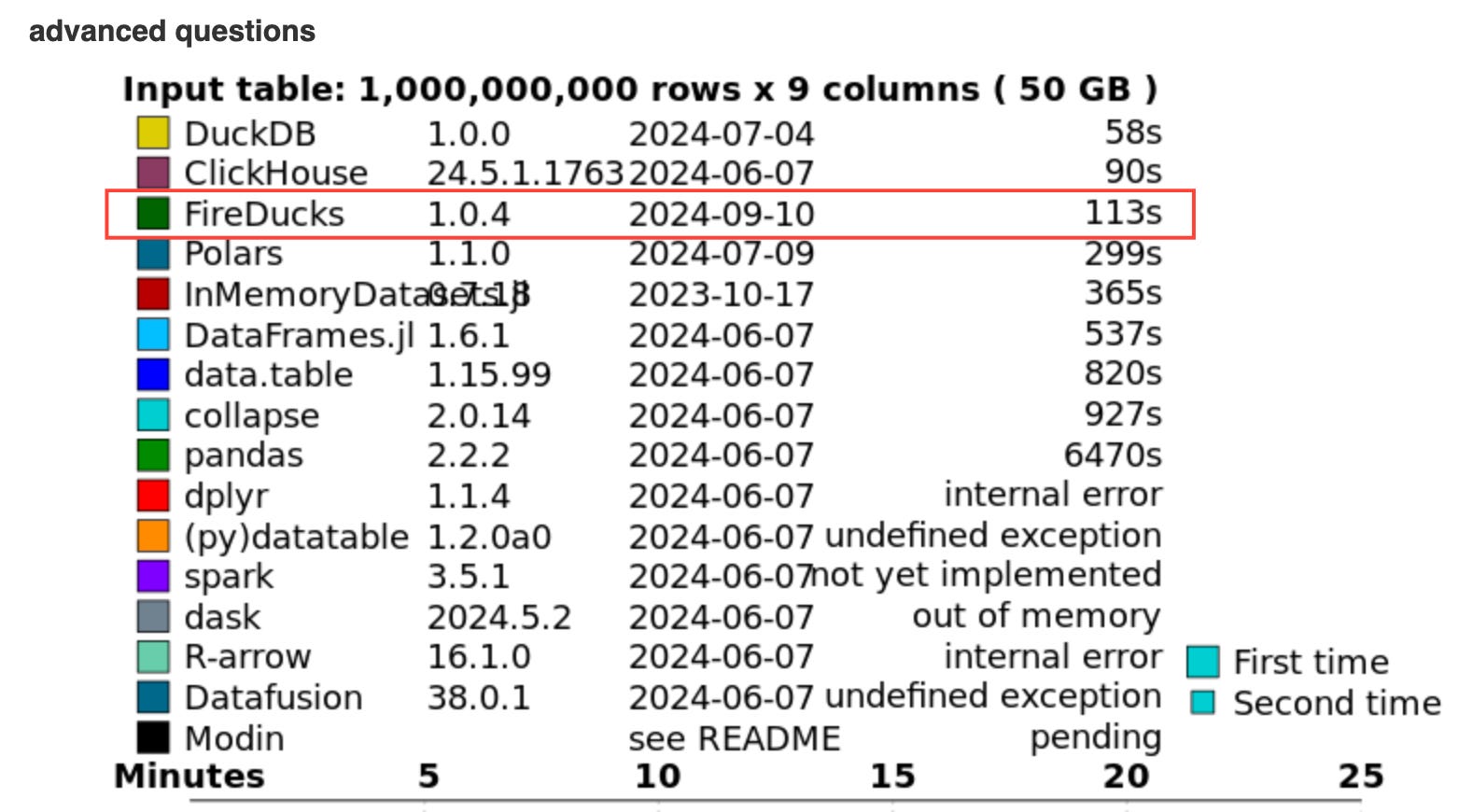
For this one, although FireDucks outperforms Polars, it falls behind DuckDB:
FireDucks: 113 seconds
DuckDB: 58 seconds
Polars: 299 seconds
Summary
Okay, looking at these numbers from both benchmarks, FireDucks is not just fast. It’s as fast as other blazingly fast DataFrame libraries like Polars and DuckDB, if not faster! These are just benchmarks, but still benchmarks.
FireDucks in Action: A Quick Look
I’d like to go through a simple code to see how FireDucks works in action. I’ll also include some useful tips along the way.
You can follow along and start from scratch, or use this Google Colab notebook in my GitHub repo.
Let’s open up a Google Colab notebook, and install FireDucks:
!pip install fireducksImport FireDucks and create a simple DataFrame using the built-in sample dataset in Google Colab:
import fireducks.pandas as pd
df = pd.read_csv('/content/sample_data/california_housing_train.csv')
df.head()Build a query and run it in FireDucks:
"""
1. Calculate the overall median income
2. Filter the DataFrame based on the criteria
3. Group by housing_median_age and calculate the average house value
"""
income_median = df['median_income'].median()
result = (
df
.query(f"median_income > {income_median}")
.query("total_rooms / households > 5")
.groupby('housing_median_age')['median_house_value']
.mean()
)
result.head()housing_median_age
1.0 190250.000000
2.0 227788.972222
3.0 239217.550000
4.0 245006.639344
5.0 242662.650407
Name: median_house_value, dtype: float64Let’s create a bar chart using a built-in pandas method:
result.plot.bar(figsize=(12, 5))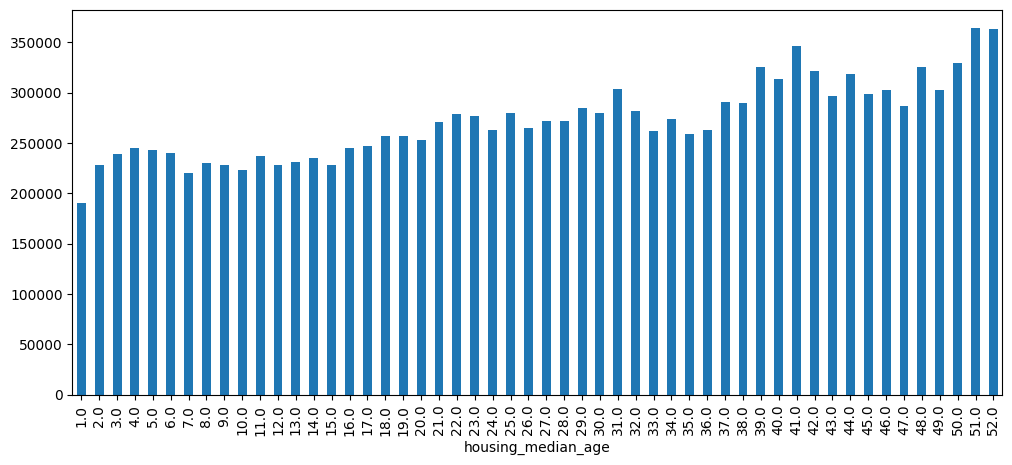
Alright, the chart worked without any issues!
Now, let’s try converting to and from a pandas dataframe:
# Converting from and to a pandas dataframe
pandas_df = df.to_pandas()
fireducks_df_from_pandas = pd.from_pandas(pandas_df)Okay, that was easy peasy.
Let’s go over some useful tips.
Firstly, you can load the FireDucks extension in your notebook to make your life a bit easier. Add the following code in a cell:
%load_ext fireducks.pandasAfter you run this code, whatever you build in pandas will be run as FireDucks. For example, the below query is in pandas, but when I check the output DataFrame, it’s actually FireDucks:
import pandas as pd
df = pd.read_csv('/content/sample_data/california_housing_train.csv')
type(df)fireducks.pandas.frame.DataFrame
def __init__(*args, **kwargs)
/usr/local/lib/python3.11/dist-packages/fireducks/pandas/frame.py
Super class of fireducks.pandas.DataFrame and Series to share
implementation.
This class does not intend to be compatible with
pandas.core.generic.NDFrame.You’ll also be able to use some magic commands after loading the extension such as
%%fireducks._verbosethat outputs the query plan before and after the optimizations are applied:
# Check the query plan before and after optimizations
%%fireducks._verbose
result = (
df
.query(f"median_income > {income_median}")
.query("total_rooms / households > 5")
.groupby('housing_median_age')['median_house_value']
.mean()
)
display(result)
Another useful magic command is
%%fireducks.profile. It helps you inspect fallbacks happening behind the scenes:
# Inspect fallbacks
%%fireducks.profile
result = (
df
.query(f"median_income > {income_median}")
.query("total_rooms / households > 5")
.groupby('housing_median_age')['median_house_value']
.mean()
)
result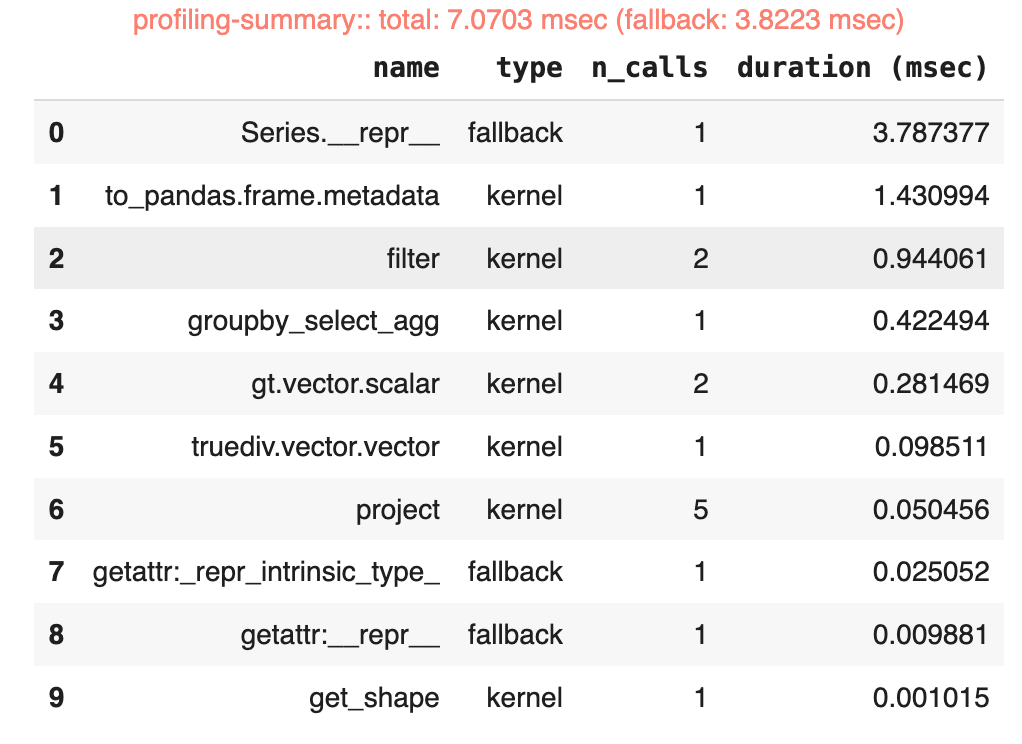
All these magic commands are great, but what if you’re just working off of a Python script? No problem, you can modify the environment variables to see the query plan, fallbacks, etc:
%%fireducks._verboseis equivalent toFIRE_LOG_LEVEL=3%%fireducks.profileis equivalent toFIREDUCKS_FLAGS="-Wfallback"
See FireDucks’ website for more information on configuring additional settings in FireDucks.
Who Should Consider Using FireDucks?
FireDucks is a great choice for existing pandas users looking to boost performance. With just a single line of code change, you can speed up your pipelines effortlessly. So you might as well do that.
Another audience could be those who previously abandoned pandas due to performance issues. With FireDucks, they can now take advantage of pandas' flexible API while enjoying significantly improved performance.
Limitations
We can't conclude this article without addressing some of FireDucks' limitations. As we all know, everything comes at a cost, nothing is truly free, and FireDucks is no exception.
FireDucks is currently only available on Linux (the x86_64 architecture). Yes, that means you can’t run FireDucks natively on Windows or Mac. Sure, you can use WSL (Windows Subsystem for Linux) or run FireDucks on a Linux VM, but that’s an unnecessary overhead for users. I personally want FireDucks to overcome this limitation sooner than later.
My suggestion to those who want to play with FireDucks is to use Google Colab notebooks like I did in my tutorial in a previous section. It’s free and it runs on Linux. You can get started right away.
There are certain pandas functions and methods that are NOT currently supported by FireDucks, such as the
applymethod. When FireDucks encounters these unsupported operations, it fallbacks to pandas internally. A fallback involves:converting FireDucks to pandas
executing the operation in pandas
converting pandas back to FireDucks
This means that when a fallback happens, the performance and memory usage may be worse than simply executing pandas code without FireDucks.You may be aware that element-wise operations can be expensive in pandas. And it’s best to utilize the built-in operations via the API. This also applies to FireDucks.
You should NOT use attribute-style column references. In pandas, you can reference columns as
df[‘A‘]ordf.A. In FireDucks, usingdf.Arequires additional processing to check whetherAis a column name, which can lead to a loss of compiler optimization.This may or may not be a limitation depending on how you look at it, but FireDucks currently is NOT open-source, though its binary is available on PyPI under the 3-Clause BSD License, permitting free use for enterprise, research, and academic purposes.
Please refer to the FireDucks’ website for more information on some of its limitations.
Conclusion
It’s a game changer that you can speed up your pandas code without changing the code itself. While I believe FireDucks' availability on major operating systems like Windows and Mac is key to its wider adoption, if you already have data workflows in pandas running on Linux, you might as well give it a try. If it doesn’t work, you can easily revert back to your original pandas code (I mean you didn’t change anything really to migrate to FireDucks anyway).
I highly recommend checking out and trying FireDucks for yourself. As mentioned, Google Colab is a great platform where you can start experimenting with FireDucks today.
To learn more about FireDucks, please refer to the following links:
If you encounter issues or you want to request new features, feel free to reach out to the FireDucks Development Team!