
Skip pandas for Your Next Project - Try Polars Instead
A faster and better alternative to pandas

pandas: The Most Popular DataFrame Library
pandas is the most popular Python dataframe library for data manipulation and analysis. If you’ve ever worked as a data analyst, engineer, or scientist, you won’t get away with not knowing pandas. pandas has been on the market for a long time and it is the first dataframe library that gained popularity.
pandas has strengths such as:
Ease of use - many resources are teaching you how to use pandas
Flexibility - there is more than one way to do things to accomplish what you want
Interoperability - strong integrations with other tools and Python libraries
However, pandas has weaknesses as well:
Not good at handling medium and large datasets - it can be pretty slow
Inefficient usage of resources
Difficult to structure code for readability
The author himself even published an article about some things he hates about pandas.
The good thing is that pandas added the Apache Arrow backend since version 2, and it surely improved some of the bottlenecks and extended pandas’ functionality. However, pandas is still not something that every data professional would enjoy using. And this is where Polars comes in.
What is Polars?
Polars is a blazingly-fast dataframe library written in Rust. Polars has a Python wrapper (Python Polars). Just like pandas, Spark, and other dataframe libraries, Polars helps you with data manipulation and processing for data analysis, science, and engineering.
One thing that’s common between pandas and Polars is that they’re designed to work on a single machine, and not for distributed workloads.
Why is it Better Than pandas?
Although the word “better” can be subjective, it’ll help you see things logically if you lay out all the components of the subject. So, let’s look at Polars’ strengths and weaknesses.
Polars’ strengths:
Parallelization by default - it’s really fast
Eager evaluation + Lazy evaluation - Polars can optimize your query
The expression API - easy to construct complex logic without suffering readability. No more too many
applymethods in your code
Polars’ weaknesses:
Lack of integrations with other tools - it’s still new, but Polars is getting integrated at a fast pace
Learning curve - there are different concepts than pandas. You want to understand them to utilize Polars to its full extent.
Lack of resources - being Polars a new tool, there are not as many resources you can use to learn it
The obvious difference between Polars and pandas is the speed/performance. Polars is blazingly fast out-of-the-box. Another key thing is that it’s easy to build complex queries, thanks to its expression API. You can chain expressions/operations one after another with ease.
Polars also lets you write your logic in SQL. This is a big plus for ETL developers and data engineers who are more comfortable writing SQL than Python.
A picture is worth a thousand words. Let’s take a look at some code examples as well as public benchmarks for performance.
Code examples
Horizontal aggregations


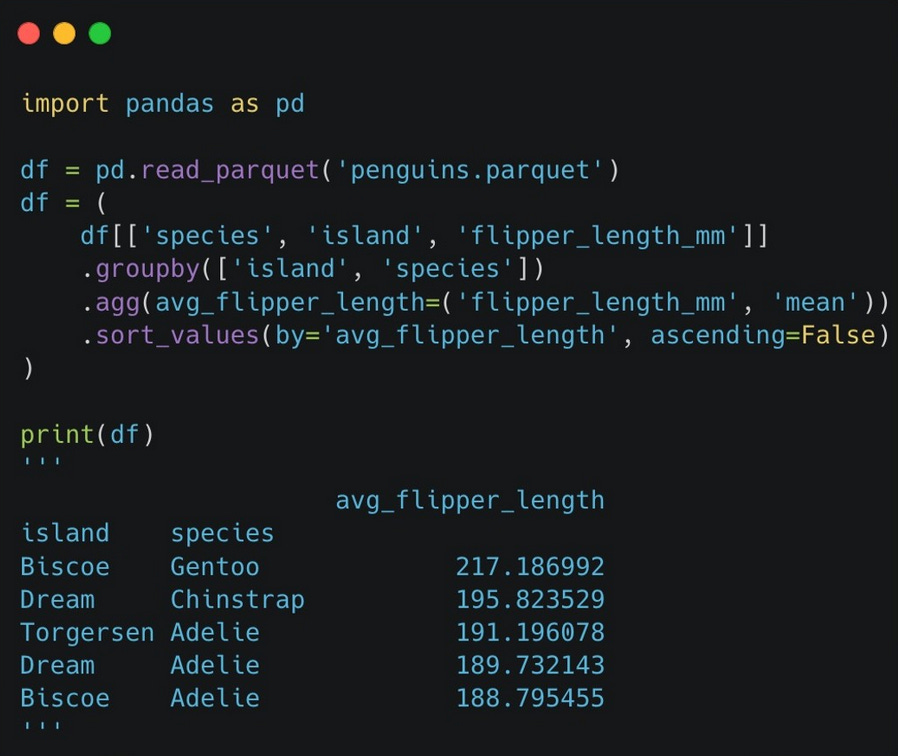
Selecting columns, grouping by, aggregations, and sorting

A window function


Which one do you think is more readable and easy to implement your logic with? Also, remember that many pandas code in the wild don’t typically use method chaining. Polars encourages method chaining by design and I believe that’s a great thing. Method chaining makes your code concise and readable.
I also appreciate how Polars centers everything around its core dataframe methods, like select, with_columns, and filter. And you build expressions directly within these methods, keeping the workflow clean and intuitive.
Whereas in pandas, you always have to pay attention to the pandas index. You may have to use a method such as reset_index reorganizing your dataframe. The assign method helps you keep your code clean when adding columns, but you may need to use a lambda function within it, which doesn’t improve your code readability.
Operations like loc and iloc for selecting columns and rows are not intuitive to follow.
Benchmarks
The H2O.ai db-benchmark done by DuckDB

The PDS-H benchmark done by Polars

A benchmark on a small dataset I did a while ago

As you can see, Polars is blazingly fast! Much more performant than pandas. The performance of pandas improves a lot by using the pyarrow backend, however, it’s still not as performant as Polars.
Also, as stated earlier, you can make use of the optimizations by using Polars’ lazyframe. pandas only supports eager evaluation.
Out-of-core processing is another thing you can utilize with Polars. Polars’ streaming API makes it possible to process your data without needing to load all your data into memory simultaneously. Simply put, you can process data larger than RAM on your machine.
Conclusion
As a Polars power user, I love working with Polars and highly recommend it over pandas for new projects. That said, don’t get me wrong - pandas is still a robust library with its place in the ecosystem. Many tools integrate seamlessly with pandas, and there are times when you have no choice but to use it. Or, you might simply stick with pandas because you already know how to accomplish something with it.
That might sound subjective, but I encourage you to try Polars for yourself to see how it performs in real-world scenarios. And let me know how you like it!
There are a few, good resources out there that I recommend:
Polars’ User Guide (website)
Awesome Polars (GitHub repo)
Polars Cookbook (book and a public GitHub repo - I wrote this book!)
Effective Polars (book)
Data Analysis with Polars (Udemy course)