
Why SQLMesh Might be The Best dbt Alternative
What is sqlmesh and why you might choose sqlmesh over dbt

If you’re in data, you probably know dbt. It’s a data transformation framework that specifically helps with the “T” of ETL/ELT. It both has open-source (dbt core) and paid offerings (dbt cloud). dbt revolutionalized and standardized the ways we structure and model data in cloud data platforms such as Snowflake, Databricks, and BigQuery. It forces you to think about things like data validation, documentation, and data lineage, which are what would be an afterthought for many data projects. Typically, the added complexity with dbt easily surpasses the benefit you’re gaining from it. And as many can attest, if you know SQL, it’s pretty easy to get up to speed with dbt (not necessarily to be an expert in it though).
However, I recently found one alternative that caught my eye, namely SQLMesh. I’ve been exploring it for the last couple of months and I’ve been quite impressed with what SQLMesh can do. Also, it’s the fact that dbt banned people from Tobiko (creators of SQLMesh) to attend Coalese 2024 tells you a lot (Toby’s LinkedIn post).
What is SQLMesh
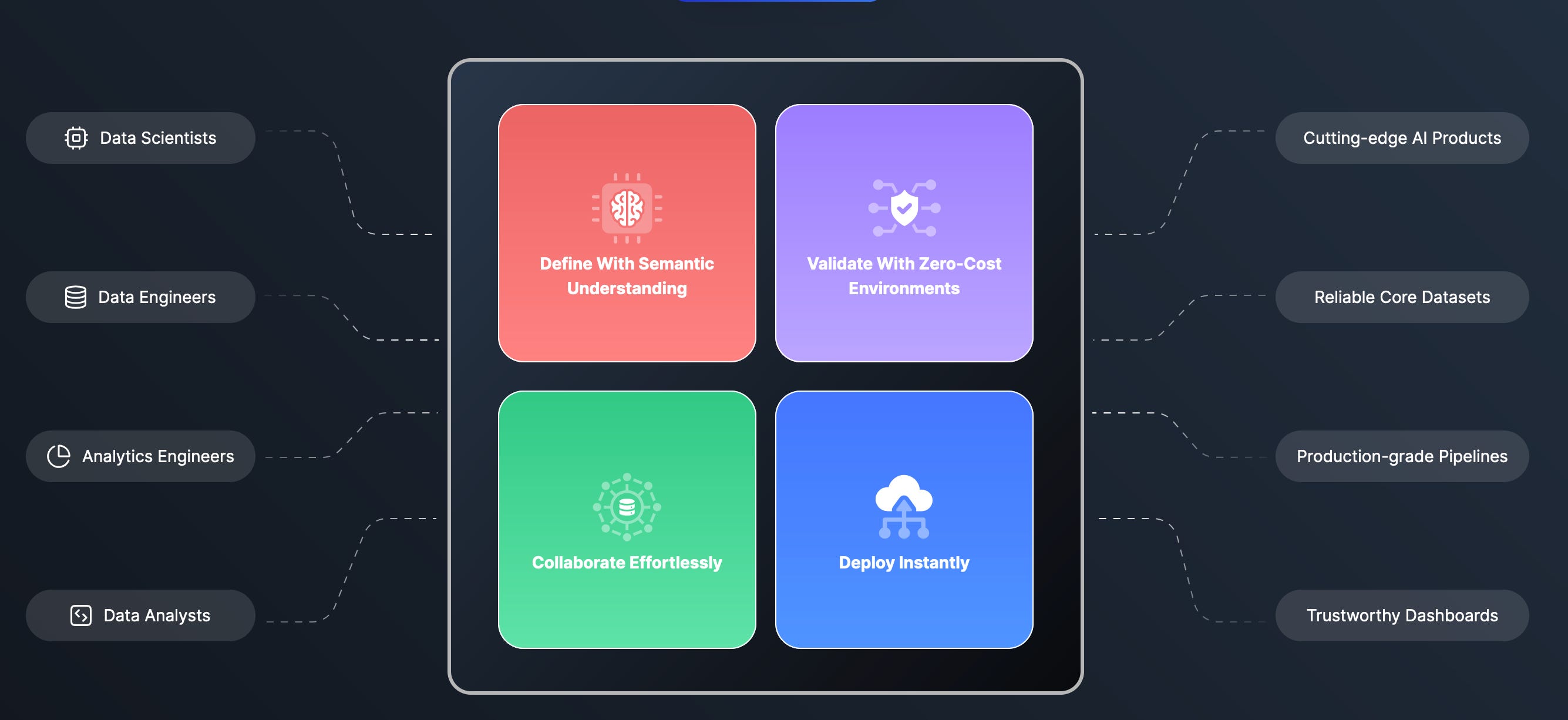
SQLMesh is a data transformation framework, just like how dbt is. It’s as simple as that, though, there are some concepts or features dbt doesn’t offer that SQLMesh offers.
You can use SQLmesh with the SQLMesh CLI, notebook, or Python APIs.
What Makes SQLMesh Better Than dbt?
Let’s go through some of the SQLMesh features.
Virtual Data Environments
They are a way to manage environments like dev and prod without creating a full copy of data. When you process data in dev, and push the changes to prod, you won’t have to re-process data again. You just switch pointers to the most updated data. This saves unnecessary, wasted computing costs. A neat way to use views.

dbt doesn’t have this concept. The only way is you duplicate your data across users and environments. This could be pretty costly.
Audits and Tests
dbt tests are audits in SQLMesh. They are for data validation. In SQLMesh, you can parameterize your audits, meaning you can make them dynamic so that an audit can easily be applied to multiple models. You can define audits within a model directly as well as define them in a separate file. Also, there are built-in audits like not_null, unique, and accepted values like they're in dbt. Another thing is that SQLMesh audits are set to stop the execution of the models when they fail, though, you can configure it to make them non-blocking.
Whereas SQLMesh tests are unit tests, where you define inputs and compare the output to expected values. This ensures your logic and code are working as expected.
SQLMesh encourages you to think about these crucial aspects upfront, ensuring robust data quality


Model Types
SQLMesh provides several, useful model types including but not limited to:
FULL
VIEW
EMBEDDED
Ephemeral model in dbt
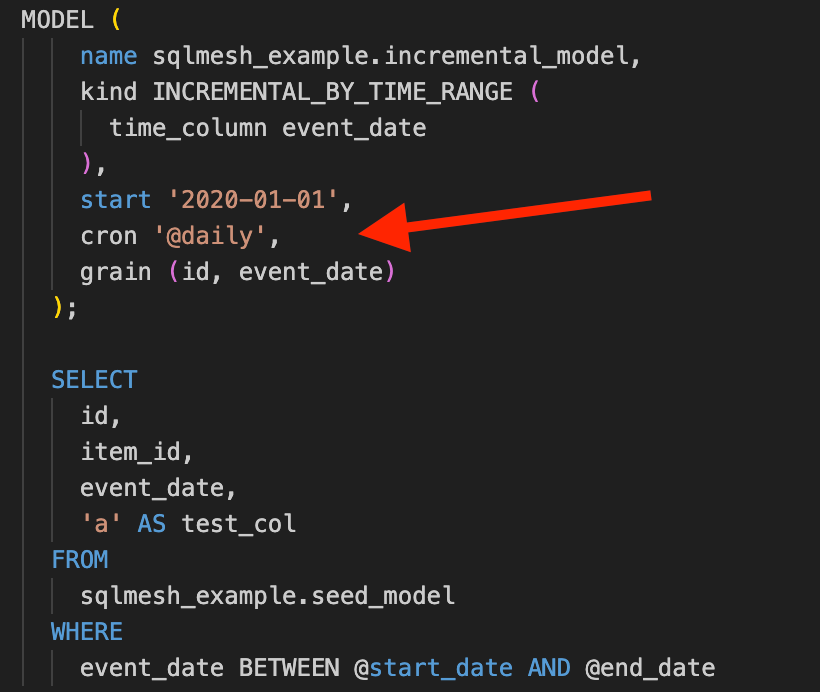
INCREMENTAL
By time range
By partition
By unique key
SCD2 (slowly changing dimension type 2)
By time
By column
This is another area where SQLMesh is ahead of dbt. It makes it easy to implement models like incremental and scd2 models. Tobiko also wrote a few articles on incremental models such as this article, explaining why dbt incremental strategy is not complete and how SQLMesh addresss this gap.
SQLMesh Plan
In dbt, there is only “dbt run“ to run models, but in SQLMesh, you have “sqlmesh plan“ and “sqlmesh run“. Here’s a short summary of what a plan is in SQLMesh:
A plan is a set of changes that summarizes the difference between the local state of a project and the state of a target environment. In order for any model changes to take effect in a target environment, a plan needs to be created and applied.
Reference: https://sqlmesh.readthedocs.io/en/latest/concepts/plans/
Simply put, you execute the “sqlmesh plan“ command to preview your changes in development, making sure they are good to be applied. Have you encountered a situation where you push changes to production, and only then things started breaking. The “sqlmesh plan“ command helps you avoid surprises like that to ensure you know what changes you’re making and how they will affect other parts of your pipeline.

The “sqlmesh run“ command is like “dbt run“, but with a key difference: SQLMesh includes its own scheduler, allowing you to define how often a model should run using cron. When your orchestrator or scheduler (e.g., Airflow, cron jobs) triggers “sqlmesh run“, it processes only the models that need to be updated. For instance, if a model is set to run daily using a cron schedule, even if your orchestrator runs “sqlmesh run“ hourly, that specific model will still only be executed once daily as defined. Again, this saves unnecessary computing cost. And all this is possible thanks to the state connection or database that keeps track of the metadata of your models.
SQLMesh UI
I typically work from the CLI, but the SQLMesh UI is pretty nice as well. In the CLI, you type “sqlmesh ui“, which opens up a browser tab like an IDE. And you can start working on the projects directly within the UI.
You just click around to execute various commands such as “sqlmesh plan“ without using the CLI. You can also see the column-level lineage and table metadata.

One suggestion I have, which I know many SQLMesh users share, is the addition of a SQLMesh extension for VSCode, similar to the one dbt provides. The SQLMesh UI is nice, but an VSCode extension will streamline the workflow even better for me.
Multi-Engine Feature
SQLMesh allows you to configure multiple engine connections. For example, you set up Snowflake as your default engine, but use duckdb for running tests locally. Or you can even set up another engine like BigQuery and use it for some models. You do that by defining and switching different “gateways“. Also, you can choose your SQL dialect used for building models.
In the below example, I have two gateways, one is named “local“ using duckdb and another one is “snowflake“ using Snowflake. And for the snowflake gateway, I configured it to use a postgres database as its state connection and duckdb for the test connection. The SQL dialect is Snowflake.

How’s this multi-engine feature even possible? It’s SQLGlot, a technology or Python library that powers SQLMesh behind the scenes. It is a parser and transpiler, meaning it can translate a SQL dialect to another.
SQLGlot also powers Ibis, a Python dataframe library that allows you to use many SQL backends with a single dataframe interface. The fact that people that are building SQLGlot is also building SQLMesh is another reason why I like SQLMesh.
The GitHub Actions CI/CD Bot
An automated CI/CD pipeline ensures smooth deployments and minimizes the risk of errors. We all know it’s essential. But it often becomes an afterthought, either because you're busy managing other priorities or you feel that your team isn’t technically ready yet. But the reality is, an automated CI/CD pipeline is something every data team aspires to implement.
SQLMesh offers an open-source GitHub Actions CI/CD bot, providing a head start for automating your data workflow deployments. Especially for those just getting started and looking to implement CI/CD practices, having a clear template and thorough documentation on how to approach it can be incredibly helpful. And it is fantastic to see this available as open-source!
First-Class Python Support
You can do pretty much anything in a Python model as long as it returns a pandas or Spark dataframe. You can be creative and build data ingestion jobs as Python models (look at this project that Mattias built).
Did you ever like writing and using a ton of Jinja and your code ended up becoming very hard to read and maintain? In SQLMesh, you define macros in Python. You can also define macros directly in a model as well.
Let’s Be Real: Pros and Cons of SQLMesh
Pros:
All the features and benefits I explained above.
Most features are open-source (e.g. CI/CD bot, column-level lineage). Their cloud offering is the managed state database as well as monitoring/debugging features and extra support (Tobiko folks let me know if you have anything else to add here).
A growing community
Cons:
A somewhat steep learning curve, compared to learning dbt, since SQLMesh has more features and technical concepts
SQLMesh does a lot more than dbt does, which can be good and bad because it means that it can be quite technical if you’re not used to thinking about data engineering stuff like CI/CD and testing
The added complexity of having to manage the shared state.
A smaller community (I love their slack community though. There is an Ask-AI channel where you can ask questions freely too)
Lack of integrations
All in all, the cons of using SQLMesh are understandable as it’s relatively a new tool. I’m excited to see how it will improve over the next few years.
Should You Choose SQLMesh over dbt?
In my opinion, if you care about the engineering aspects of building the data pipelines (which you should), or if data engineers are the ones creating and managing the “T“ then you should go for SQLMesh.
Do you need a wide suite of integrations across many data plaforms and tools and/or want to use something with a bigger, mature community? Then you might want to go wth dbt.
In short, I’d say that whether you should choose SQLMesh or dbt, comes down to the added complexity of SQLMesh is worth it for you and your team. Intergrations with other tools and community maturity will eventually catch up.
I should note that SQLMesh is dbt compatible, meaning you can use SQLMesh on top of your existing dbt project as a wrapper, utilizing SQLMesh’s features such as data virtual environments. Perhaps you might give it a try and see how you like SQLMesh?
Also, don’t forget that SQLMesh does NOT make you write a ton of yaml and Jinja. Some people like to have everything in yaml, but I prefer defining metadata directly in model files. Less context switching is better for me. I also never liked Jinja’s syntax. SQLMesh lets me use pure Python, which is a big plus.
Conclusion
To me dbt vs SQLMesh is like pandas vs Polars. Polars is obviously better (correct me if I’m wrong!), but it still needs to catch up on integrations, adoption, and interoperability with other tools. And so is SQLMesh. It’s still a relatively new tool, and it needs a growing user base to truly reach its potential. I’ll continue exploring SQLMesh and sharing my learnings along the way.
Now the title should change to “Why dbtMesh is a great alternative to SQLbt” 😅😂
This might change with dbt’s acquisition of SDF