
A Quick Overview on DuckLake: Yet Another Table Format
A Lakehouse without traditional lakehouse complexity

I hope I’m not too late to talk about Ducklake. It is yet another table format along with Iceberg and Delta tables. DuckLake is created by the DuckDB team and is open source.
In this article, I hope to answer questions like:
How do you get started with DuckLake?
How is it different than Iceberg and Delta?
Why should you choose DuckLake?
Here’s the GitHub repo that contains the code used in this article.
What is DuckLake?

DuckLake is an integrated data lake and catalog format.
That’s what the official Ducklake website says. In my own words, DuckLake is a new, open source lakehouse table format powered by the Parquet file format and a SQL transactional database like Postgres.
Yes, we already have Iceberg and Delta tables. The catch with DuckLake is that it offers lakehouse features without the traditional lakehouse complexity, and I think that’s huge.
You often hear all about lakehouses, but few people actually know how to implement one in practice on your own. There’s still a good deal of complexity involved, especially when it comes to hosting and managing a metadata catalog. And that's why people opt to using managed solutions like Databricks, Starburst, etc.
DuckLake changes that. It makes building your own lakehouse much simpler.
How Is DuckLake Different Than Iceberg and Delta?
If you think about the underlying query engine(s) that each table format supports, you’ll have a good idea of what each might be best suited for.
For example, DuckLake is only supported by DuckDB (at least for now). And DuckDB is built for simplicity and local-first analytics. Iceberg and Delta are supported by engines like Spark, Flink, Trino, etc. And they’re large-scale distributed query engines.
With Iceberg, managing your Iceberg catalog is definitely an operational overhead. Some level of complexity also comes with engines like Spark and Trino. DuckLake manages metadata via an OLTP database like Postgres, which simplifies the management of the metadata catalog.1
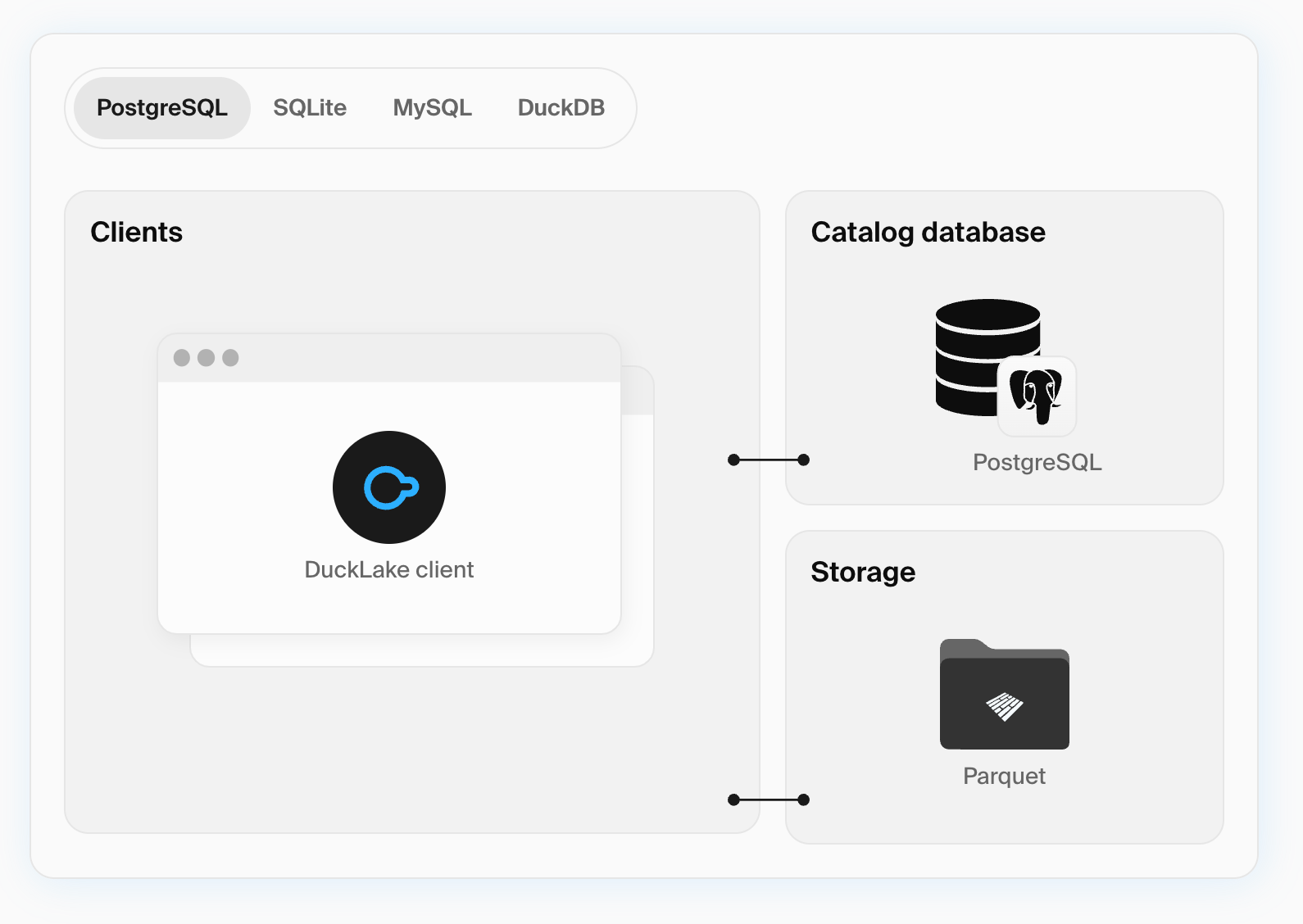
Delta doesn’t require a catalog, which is very neat, but there is still a risk for vendor lock-in (although Databricks open sourced both Delta lake and Unity Catalog, how “open source” are they?). Also, Delta’s ecosystem mainly adopted by the Spark community .
DuckLake is a great fit when you want a fast, no-fuss lakehouse experience with DuckDB. If you need scale, engine interoperability, or advanced data governance, Iceberg or Delta may be a better choice.
How Do You Get Started?
Let me show you a simple script to build a table using DuckLake in my local file system:
import duckdb
def main():
duckdb.sql("""
INSTALL ducklake;
LOAD ducklake;
ATTACH 'ducklake:metadata.ducklake' AS my_ducklake (DATA_PATH 'ducklake_data_duckdb_local/');
USE my_ducklake;
CREATE or REPLACE TABLE my_table AS SELECT 1 AS my_number;
""")
print(
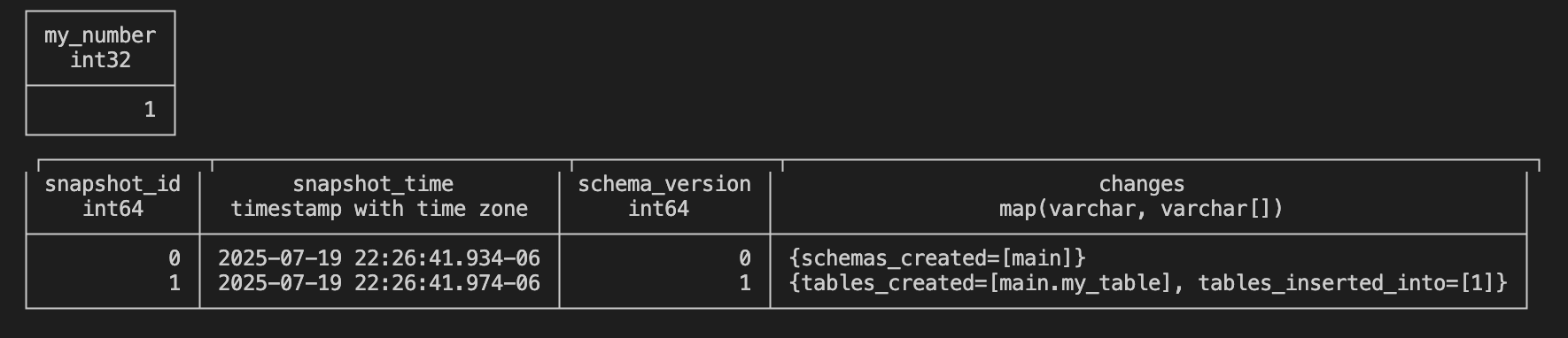
duckdb.sql("SELECT * FROM my_table;"),
duckdb.sql("SELECT * FROM ducklake_snapshots('my_ducklake');")
)
if __name__ == "__main__":
main()Output:
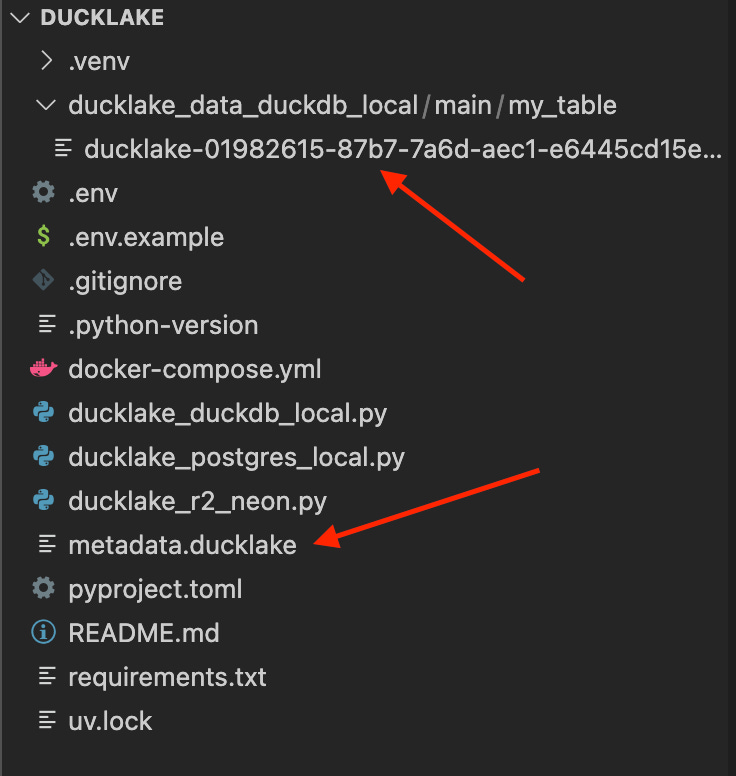
You get a few new files in your directory (as I configured in the “ATTACH“ statement above):
In this script, I just did:
Install the DuckLake plugin
Attach a DuckDB database to be used as the metastore
Create a table and read data from it + read snapshots data from the metastore
That’s it. Dead simple. Your 2 yr-old toddler can even spin up DuckLake in 3 min (jk, if your 2yr-old can do that he/she is genius). What’s awesome is that it just works.
And that is the easiest and quickest way to play with DuckLake, using your local filesystem (for storing parquet files) and DuckDB (metastore). I literally encountered zero errors or issues running this script at my first try. For any production use case, you’d likely be using something like S3 and Postgres database instead. Which I’ll show you a simple example in a moment.
But before that, let’s spin up a Postgres instance locally and use it as the metastore this time. Still doing everything locally though:
import duckdb
import os
import dotenv
dotenv.load_dotenv(override=True)
def main():
host = os.getenv('HOST', 'localhost')
port = os.getenv('PORT', '5432')
user = os.getenv('USER', 'ducklake_user')
password = os.getenv('PASSWORD', 'ducklake_password')
dbname = os.getenv('DBNAME', 'ducklake_catalog')
duckdb.sql(f"""
INSTALL ducklake;
LOAD ducklake;
INSTALL postgres;
LOAD postgres;
ATTACH 'ducklake:postgres:dbname={dbname} host={host} port={port} user={user} password={password}' AS my_ducklake (DATA_PATH 'ducklake_data_postgres_local/');
USE my_ducklake;
CREATE or REPLACE TABLE my_table AS SELECT 2 AS my_number;
""")
print(
duckdb.sql("SELECT * FROM my_table;"),
duckdb.sql("SELECT * FROM ducklake_snapshots('my_ducklake');")
)
if __name__ == "__main__":
main() Make sure you have your Postgres instance running locally before running the script. The only difference between the first script and this one is using DuckDB or Postgres as the metastore. The output will be the same except the output value from the table is 2 in this script instead of 1.
Finally, here’s another script using Cloudflare R2 and Postgres database on Neon. If you want to test it out, makes sure you put in your creds in the .env file.
import duckdb
import os
import dotenv
dotenv.load_dotenv(override=True)
def main():
duckdb.sql(f"""
INSTALL ducklake;
LOAD ducklake;
INSTALL postgres;
LOAD postgres;
CREATE SECRET (
TYPE r2,
KEY_ID '{os.getenv('R2_ACCESS_KEY_ID')}',
SECRET '{os.getenv('R2_SECRET_ACCESS_KEY')}',
ACCOUNT_ID '{os.getenv('R2_ACCOUNT_ID')}'
);
ATTACH 'ducklake:postgres:dbname={os.getenv('DBNAME')} host={os.getenv('HOST')} port={os.getenv('PORT')} user={os.getenv('USER')} password={os.getenv('PASSWORD')} sslmode=require' AS my_ducklake (DATA_PATH 'r2://{os.getenv('R2_BUCKET_NAME')}/ducklake/');
USE my_ducklake;
CREATE or REPLACE TABLE my_table AS SELECT 3 AS my_number;
""")
print(
duckdb.sql(f"SELECT * FROM my_table;"),
duckdb.sql("SELECT * FROM ducklake_snapshots('my_ducklake');")
)
if __name__ == "__main__":
main()
Again, there is not much difference in the code. This one needs to add R2 secrets and configure the object file path, but that’s pretty trivial as it sounds.
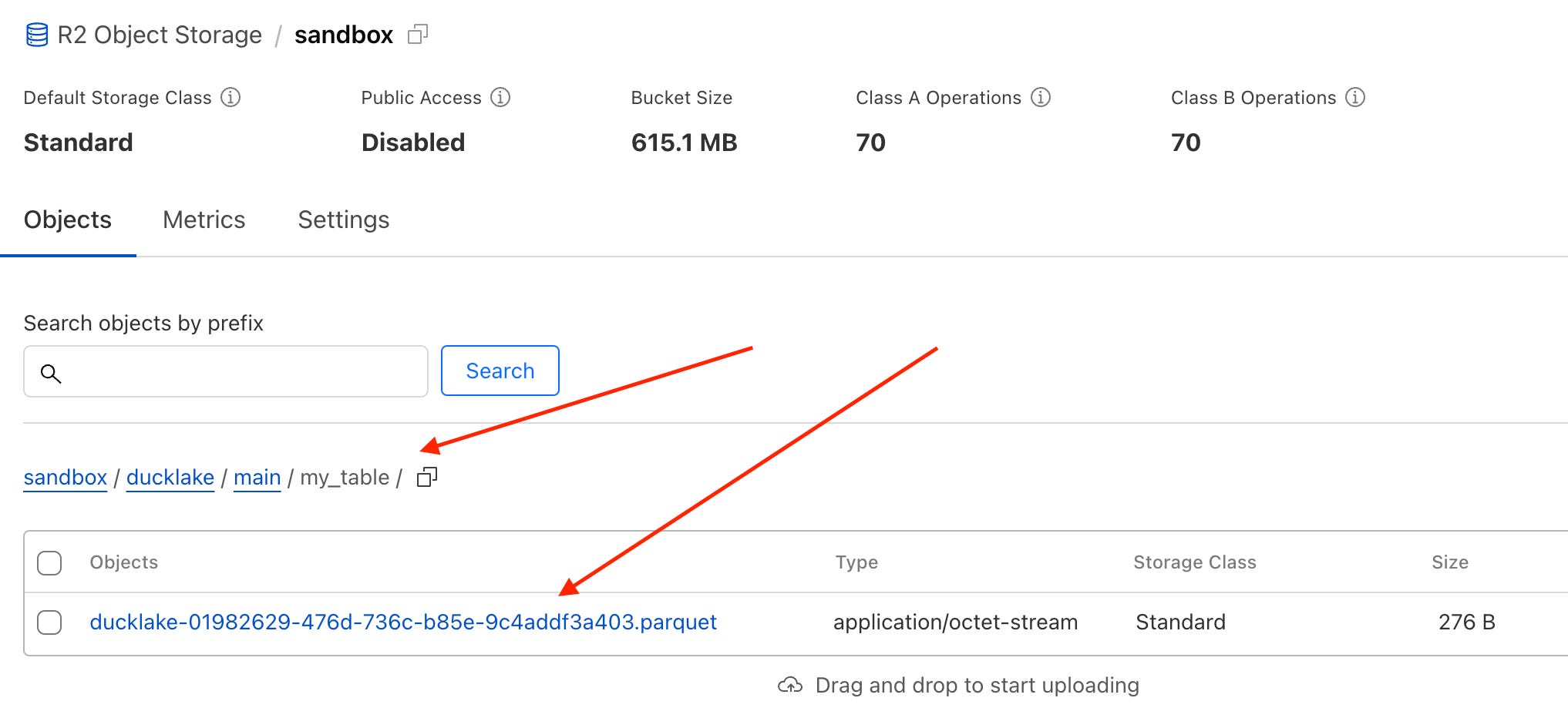
After running the script, you can see the output file added in your R2 bucket:
Also see the list of DuckLake tables populated in my Postgres instance on Neon:
Do you see how simple it was to use DuckLake with a remote object storage (R2) and a Postgres instance in the cloud (Neon)?
Simplicity is what makes DuckLake a big deal.
Should You Use DuckLake?
Don’t ask me! Jk, but not jk. Obviously, you’ll need to weigh the pros and cons of each solution and come to your own conclusion. But if you’re already using DuckDB and starting to need some sort of transactional capability, then DuckLake is what you need.
I know a few folks in my network who jumped on DuckLake right off the bat and I personally would’ve used it in one of my consulting projects if it had existed at the time. If you’re utilizing local compute a lot, then DuckLake would be a potential fit.
DuckLake is not mature as a product yet. Looking at the still-growing Iceberg ecosystem as well as the established Delta community, DuckLake doesn’t have that yet. So, that’s definitely something to consider.
Also, if you’re already using Delta or Iceberg and it’s working well then I don’t think there is a need to switch over. That’d probably cost you a lot more than what you gain. My guess is there will be integrations coming our way across these formats with DuckLake (Like Apache XTable). You don’t need to rush to make a big change now.
For those who’re concerned about the overall adoption of DuckLake and the speed at which the data industry adopts it, here’s the good news - MotherDuck already built their managed DuckLake. And this integration is already supported by dlt and Estuary. Also, SQLMesh works with DuckLake out of the box. This tells us how easy it might be to built integrations around DuckLake where DuckDB is used.
Conclusion
DuckLake is an exciting, new technology that may change the way you build your lakehouse. If you’re curious, try it yourself and see how you like it. The code I used in this article should be a good starting point and gets you started right away.
We live in exciting times. Let’s see what other innovations and adoptions are coming to us in this lakehouse realm.
I know there is an option to use an OLTP database as metastore with Iceberg. I don’t have enough experience to say anything on this, or how complete and supported it is. Let me know if you have experience with it. I’d love to learn more about the pros and cons of that approach in Iceberg, and compare that with DuckLake.