
SQLMesh Makes Your Data Validation Easy
The table diff feature makes your data validation a breeze

I’ve been using SQLMesh for work projects for the past couple/several months. I’m impressed with their table diff feature, which can compare the data of your model before and after your changes. I hope to explain and demonstrate how useful this feature might be in this article.
What is Table Diff?
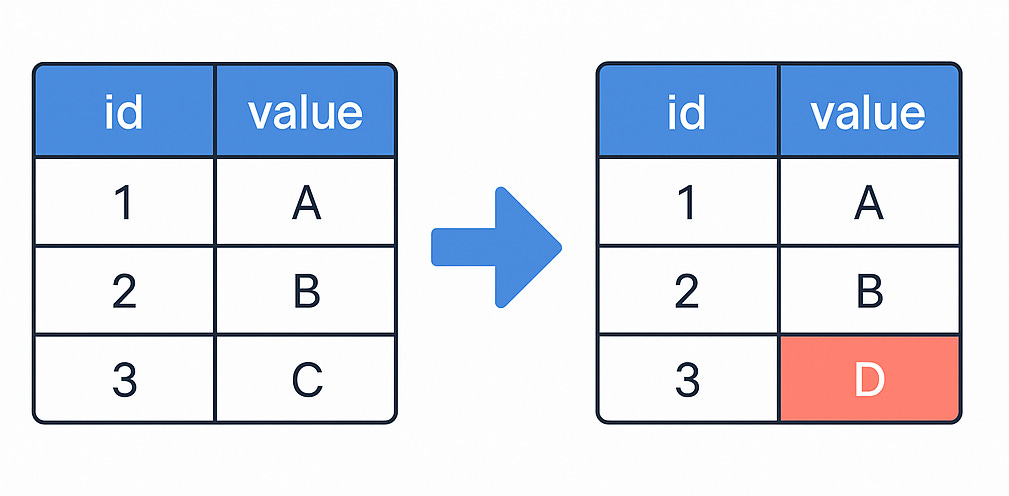
Table diff is a feature or tool that allows you to compare two database tables to find differences in their schema (structure) and/or data (values). This helps a ton when you make changes in your model because you can make sure it doesn’t produce an unexpected output. Think table diff as an extra layer on top of your unit test1.
SQLMesh has many cli commands such as “sqlmesh plan”, “sqlmesh run”, etc, and “sqlmesh table_diff” is one of them.
What Does it Allows You To Do?
Table diff lets you:
Compare the schema and data of two data objects (tables or views).
Validate models. e.g. comparing a model in two different environments (like prod vs dev) or comparing tables/views.
Detect differences such as:
Schema diff: which columns have been added, removed, or had type changes between the two objects.
Row diff: which rows differ (in value) or exist only on one side, by joining the two objects and comparing matching columns.
When Should You Use it?
TLDR; You can use it anytime you need to prove that two datasets are equivalent or to precisely measure how they differ. But if you’re interested in a longer explanation, here are a few examples:
Before promoting changes
Compare a model in dev vs prod to confirm that a code change doesn’t alter the data unexpectedly. e.g. You refactor a transformation table diff shows whether only column names/types changed, or if row values differ.
Cross-environment validation
After moving data to a new warehouse, check that the migrated tables are identical to the originals. Validate that staging, QA, and prod environments are consistent.
Model or pipeline refactoring
When you optimize/rewrite a query, use table diff to verify outputs stay the same, to prevent introducing subtle business logic changes.
Limitations
There is no free lunch! Not that I’ve experienced all of these in a project, but here are some things to keep in mind when using table diff in SQLMesh:
Grain requirement: You need a unique key (grain) for correct row matching (though you could disable the check for a primary key with
--skip-grain-check).Data type handling: Some complex or nested types (arrays, structs) may not be fully supported across all engines. Type differences (e.g. timestamp precision) can also cause false mismatches.
Performance on large tables: Full outer joins on big tables can be slow and costly. Sampling or filtering is often suggested.
Floating-point precision: Small rounding differences may appear as mismatches unless you control precision with
--decimals.Cross-database diffs: SQLMesh executes models within a single database system, specified as a gateway. Cross-database table diffing is only available in SQLMesh’s paid product, Tobiko Cloud.
Table Diff in Action
Alright, let’s test out the table diff feature.If you’re not familiar with SQLMesh at all, I suggest you look at this other article walking you through how to use SQLMesh. The final state of the project code is found in this repo.
Overview
The first step is to start up a SQLMesh project on your own, which would generate 3 example models that are auto-created in the project. Doesn’t matter which engine you use, but DuckDB would be the most straightforward and requires the least configuration upfront.
In this project, we’ll be looking at full_model. This model’s source data is seed_data.csv under seeds folder and the data looks like this:
id,item_id,event_date
1,2,2020-01-01
2,1,2020-01-01
3,3,2020-01-03
4,1,2020-01-04
5,1,2020-01-05
6,1,2020-01-06
7,1,2020-01-07And it flows through seed_model.sql, incremental_model.sql and to full_model.sql.
You see the following output after you run sqlmesh plan, and sqlmesh fetchdf to see the model output:
$ uv run sqlmesh fetchdf “select * from sqlmesh_example.full_model”
item_id num_orders
0 1 5
1 3 1
2 2 1The model has been materialized in my prod environment.
Modifying the Model and Confirming the Changes
Okay, let’s modify the model and apply the changes in dev environment. We’ll do 2 things:
Add a new column called “
new_col_one“Multiply the
num_ordersfield by 2 (and remove tests/test_full_model.yaml since this test will fail after making this change)
After making these changes, the model definition looks like this:
MODEL (
name sqlmesh_example.full_model,
kind FULL,
cron ‘@daily’,
grain item_id,
audits (assert_positive_order_ids),
);
SELECT
item_id,
COUNT(DISTINCT id) * 2 AS num_orders,
1 as new_col_one
FROM
sqlmesh_example.incremental_model
GROUP BY item_idAnd let’s run a few commands:
$ uv run sqlmesh plan dev$ uv run sqlmesh fetchdf “select * from sqlmesh_example__dev.full_model”
item_id num_orders new_col_one
0 3 2 1
1 2 2 1
2 1 10 1Notice that the changes are in the dev model as expected.
Using Table Diff Before Deploying the Changes into Production
It’s time to use the table diff feature. Remember, we made changes in the model in dev, but in prod, the model still doesn’t have those new changes. This table diff features helps us see exactly what’s changed:
$ uv run sqlmesh table_diff prod:dev sqlmesh_example.full_model
Models to compare:
└── sqlmesh_example.full_model
Calculating model differences ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100.0% • 1/1 • 0:00:00
Table diff completed successfully!
Table Diff
├── Model:
│ └── sqlmesh_example.full_model
├── Environment:
│ ├── Source: prod
│ └── Target: dev
├── Tables:
│ ├── Source: db.sqlmesh_example.full_model
│ └── Target: db.sqlmesh_example__dev.full_model
└── Join On:
└── item_id
Schema Diff Between ‘PROD’ and ‘DEV’ environments for model ‘sqlmesh_example.full_model’:
└── Added Columns:
└── new_col_one (INT)
Row Counts:
└── PARTIAL MATCH: 3 rows (100.0%)
COMMON ROWS column comparison stats:
pct_match
num_orders 0.0Okay, there is so much information in this output. Let’s review a few things:
Table diff join on “
item_id”, which is what we set as the grain of the model.Schema diff between the environment I specified in the cli command, which are prod and dev.
It shows the added columns, matched/unmached row counts, and the percent of common/matched rows.
Isn’t this fantastic? How awesome is it that there is an automatic way to make sure the changes you’re trying to make won’t affect production models in an unexpected way?
And there is more. There are several parameters you can throw in the table_diff command, such as —show-sample, which would give you a sample rows on top of all these stats you just saw in the output. You can see the full list of params in this doc.
Deploying the Changes to Production
Typically you’d have a development process set up so that you only run dev changes locally and prod changes are deployed through your CI/CD processes. But in this project we don’t have that kind of fancy stuff, so we’ll deploy the changes to production locally. For that, we’ll just run the sqlmesh plan command like we did at the beginning of this project. And this time, let’s explicitly specify prod env:
$ uv run sqlmesh plan prod
Differences from the `prod` environment:
Models:
└── Directly Modified:
└── sqlmesh_example.full_model
SKIP: No physical layer updates to perform
SKIP: No model batches to execute
Updating virtual layer ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100.0% • 1/1 • 0:00:00
✔ Virtual layer updatedOnly the virtual update was done (since we’d already materialized these changes in dev), which is another huge benefit of using SQLMesh!
Conclusion
A feature like table diff makes a difference in your development and gives you confidence in what you’re delivering. Sure, you can invent a table diff tool on your own or use something else on the market, but what I love about table diff in SQLMesh is the fact that it’s built right in SQLMesh! This doesn’t sound like a big deal, but it’s a big deal (at least for me).
Lastly, if you want to take a look at table diff in SQLMesh these are the docs:
Unit tests are to test a part of your model based on the input you give it, to see if it returns the expected output.