
DuckDB vs. FireDucks vs. Polars: Which One is the Fastest?
An unofficial benchmark of single-node data processing engines

This article is delivered in partnership with the FireDucks Development Team at NEC’s R&D department.
In my last article on FireDucks, I discussed what it is and what benefits you might get from using it. I also introduced a few benchmarks that compared FireDucks with others tools like DuckDB and Polars.
In this article, I’ll walk you through the benchmark I did on my own. Oftentimes, benchmarks you see in public don’t represent much of the actual reality and I always like to test it myself. Simply put, this article may be for my own learning, which I hope helps with yours, too.
I’ll try to be as transparent as I could in how I did what I did for the benchmark. Let me know if you see any issues or feedback on my scripts for the benchmark.
You can get the source code and full instructions in this GitHub repo.
Setup
Data
This benchmark uses 2023 Yellow Taxi Trip Data, which contains 38 million rows and 19 columns. The dataset is approximately 4GB on disk (in CSV).
Machine Specs
The benchmark results, shown in a later section, were obtained in a Docker container running (using the manylinux_2_34_x86_64 image) on a EC2 instance with 64GB RAM and 16 vCPUs and 16GB of EBS volume (m6i.4xlarge).
Library Versions
duckdb==1.2.1
fireducks==1.2.5
polars==1.24.0
Queries
The benchmark includes 3 types of queries:
Simple Aggregation: Basic aggregations (sum, mean, min, max) on the
total_amountcolumnGroupBy Aggregation: Aggregations (sum, mean, min, max) of
total_amountgrouped byVendorIDandpayment_typeJoin: Join the original table with aggregated
total_amountsums (grouped byVendorID,payment_type, andpickup_month)Window Functions: Two window calculations:
Average
fare_amountperVendorIDDense rank of trips by
total_amountwithin eachpayment_typepartition
All queries are run with I/O, meaning that each time a benchmark function is executed, the code reads the file from disk. This approach allows us to evaluate the efficiency of each tool's optimizations, such as predicate pushdown and projection pushdown.
If you’re interesting in looking at each query, please refer to my GitHub repo.
Results
The following visuals are the resulting output. Just a note that the script runs each query 3 times and calculate the average timing.
CSV:

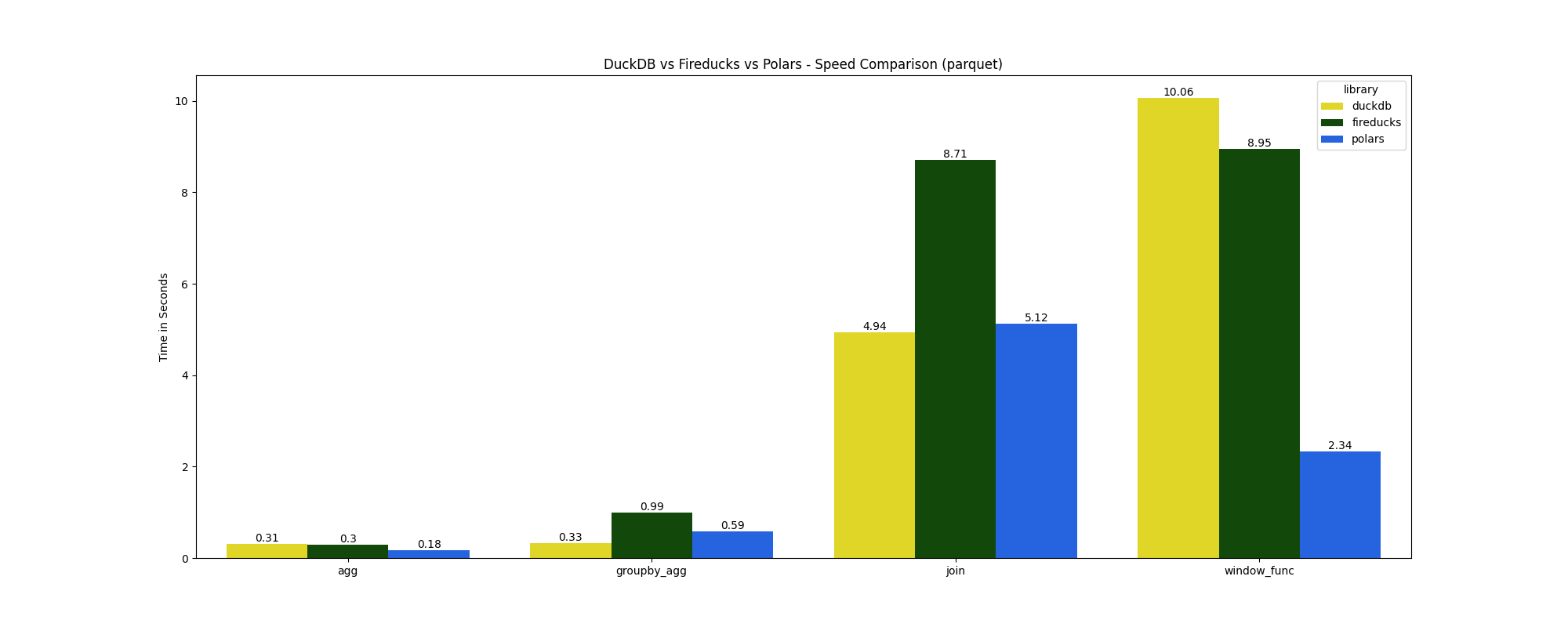
Parquet:

Here are a few of my observations:
Overall, all three libraries are comparable in speed.
FireDucks performed on par with the others, faster than DuckDB for most queries, except for the join operation on the Parquet file.
Both FireDucks and Polars excelled in window function queries, running about 3–5 times faster than the other DuckDB. DuckDB somehow struggled with these window function queries.
How To Run This Benchmark On Your Own
The benchmark supports both CSV and Parquet files. You can download the CSV file from the site mentioned above, but if you want to test performance using a Parquet file, you'll need to convert the CSV to Parquet first (you can use the conversion script I added to the project).
Make sure to place them in the data directory. You may need to change the dataset name in this specific line of code depending on how you name your source files.
You may want to run this on a Linux machine with the x86_64 architecture, which natively supports the manylinux image, because FireDucks only runs on it. You could also run this on macOS1 (I haven't tried Windows) since the project/code is already packaged in a container with the manylinux_2_34_x86_64 image, but in which case, you'll need to use the
polars-lts-cpupackage instead of the regular Polars package since MacOS relies on x86_64 emulation for this setup.
Here’s what you need to do to run this benchmark on your own:
Make sure you have Docker/Docker Compose, Git, and Python installed on your machine
Clone the repo
Navigate to the project directory with
cd duckdb-vs-polars-vs-fireducksPlace the files in the data directory (the code expects these source files to be named as:
2023_Yellow_Taxi_Trip_Data.csvor2023_Yellow_Taxi_Trip_Data.parquet
Run the benchmark with:
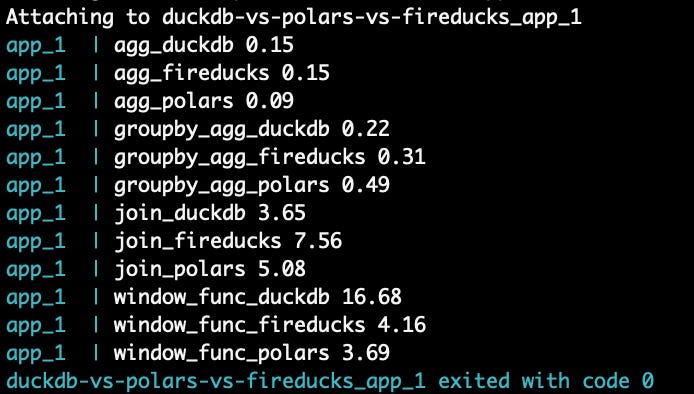
# run the benchmark with Parquet FILE_TYPE=parquet docker compose up # with CSV docker compose upYou’ll the result in the terminal as each query finishes running:

To see the result in a bar chart, you may need to copy the png file from inside the container to your local filesystem by executing:
# copy the file to your local filesystem docker cp <container_id>: <local_path> # e.g. docker cp cbd3dc6ea3f8b71be0497123b7c919a940655bd9fc04c47bd375c35966327088:app/output_parquet.png ~/Downloads/output_parquet.png
Notes
The benchmark evaluates in-memory execution and does not test streaming or out-of-RAM processing.
Benchmarking DuckDB queries uses
.arrow()to materialize results, as it was the fastest among.arrow(),.pl(),.df(), and.fetchall().While
.execute()could be used, it might not properly reflect full execution time as the final pipeline won't execute until a result collecting method is called.For more details on DuckDB materialization, see this Discord discussion.
Polars uses
.collect()to materialize results.FireDucks uses
._evaluate()to ensure query execution.The benchmark uses the newest versions of each library as of 03/13/2025.
All libraries were tested with their default settings and no manual optimizations.
The goal was to compare "out of the box" performance with straightforward query implementations.
Conclusion
Overall, DuckDB, Polars, and FireDucks performed on par in most benchmarks, with each tool excelling in different areas. FireDucks and Polars stood out in window function queries, showing a big performance advantage. FireDucks kept up well with the others, except for the join on the Parquet file. Meanwhile, DuckDB struggled with window functions but remained competitive in other operations.
The choice between these tools ultimately depends on your specific workload and ecosystem fit. If you want a flexible API without compromising on speed, Polars is the way to go. DuckDB is ideal for SQL-centric data processing pipelines. And if you’re looking to speed up your pandas code with minimal effort, FireDucks is your best choice.
I ran the benchmark on my Mac (M1, 64GB RAM, 10 cores), and the following screenshots are the results. Overall, all three libraries were slightly slower, likely due to the emulation overhead (except that window functions for DuckDB outperformed the ones on Linux).
CSV:

Parquet:
It's hard to be Rust based Polars. SQL people will gravitate to DuckDB, the others Polars.