
Understanding Microsoft Fabric
A guide for those new to Microsoft Fabric

I’m sure you’ve heard about Microsoft Fabric by now. It was first launched in 2023 and has been in existence for almost two years.
Some of you may use Microsoft tools at work. Some of you may not be aware of or don’t care anything about Microsoft, but you’ve heard about Microsoft Fabric and are confused about what problems it solves for you. If this is you, you came to the right place. I’ll walk you through the concepts and ideas around Microsoft Fabric. You’ll better understand it by the end of this article and perhaps have a use case for it.
I’ve been exploring (mostly in mid-2024) Microsoft Fabric since its launch and have even given talks at a few conferences (Power BI & Fabric Summit 2024 and SQL Saturday SLC 2024).
Although I haven’t had a chance to implement Fabric in production yet, I’ve talked to several folks who have been using Fabric at work. I gained a lot of insights through these discussions as well as my own research and exploration. It’s been great to learn about what Fabric has to offer and the challenges around its implementations and actual use cases.
(In this article, I’ll refer to “Microsoft Fabric” as “Fabric”)
A note that I won’t be able to cover everything about Fabric such as brand new features. I’ll focus on helping you understand the core of Fabric.
Introduction to Microsoft Fabric
Microsoft puts it as:
Microsoft Fabric is an end-to-end analytics and data platform designed for enterprises that require a unified solution.
(https://learn.microsoft.com/en-us/fabric/get-started/microsoft-fabric-overview)
Or let me try to explain in my own terms.
Microsoft Fabric is the Microsoft version of Databricks or perhaps the fully realized Azure Synapse Analytics it never became.
That’s it. It’s as simple as that.
Both Databricks and Fabric are built on the lakehouse architecture utilizing the concepts around data lake and data warehouse. Microsoft Fabric has a quite a few components though. We’ll go through them in a min.
Core Components of Microsoft Fabric
There are many components in Fabric. They might’ve confused you when you first heard about Fabric, so let me decompose one by one.
OneLake
Data Factory
Data Engineering
Data Science
Data Warehouse
Real-Time Intelligence
Power BI

OneLake
A single, logical data lake that spans all Fabric workloads. A unified data lake.
Compatible with Delta Lake format and allows direct access via shortcuts (linking to external storage like Azure Data Lake and AWS S3).
Eliminates data duplication by virtually unifying storage across services.
Data Factory
A serverless data integration tool for moving and transforming data. ETL/ELT & Orchestration.
Provides low-code and code-first capabilities with:
Data Pipelines (ETL orchestration)
Dataflows (low-code, Power Query-based transformations)
If you know Azure Data Factory, this it the Fabric version of it.
Data Engineering
A serverless Apache Spark-based platform for data wrangling, transformations, and ETL.
Provides notebooks for developing scalable data pipelines.
You may use a Fabric item called “Lakehouse“ to store, organize and serve data (imagine a database with schemas, table etc stored in files like Databricks). Spark notebooks work with data in this Lakehouse.
Data Science
A collaborative machine learning and AI workspace in Fabric.
Uses notebooks and Spark for ML training & experimentation.
Data Warehouse
A fully managed, serverless SQL-based data warehouse.
Designed for fast analytics on structured data.
You may use a Fabric item called “Warehouse“ to store, organize and serve data (imagine a columnar SQL database with schemas, table etc stored but is still backed by files). And you write sql to work with data in this Warehouse.
Real-Time Intelligence
A managed event processing system that ingests data from sources like IoT devices, logs, or external APIs in real time.
This utilizes KQL Database (Kusto Query Language).
Power BI
Microsoft’s business intelligence & visualization tool embedded in Fabric.
Provides self-service and enterprise BI capabilities.
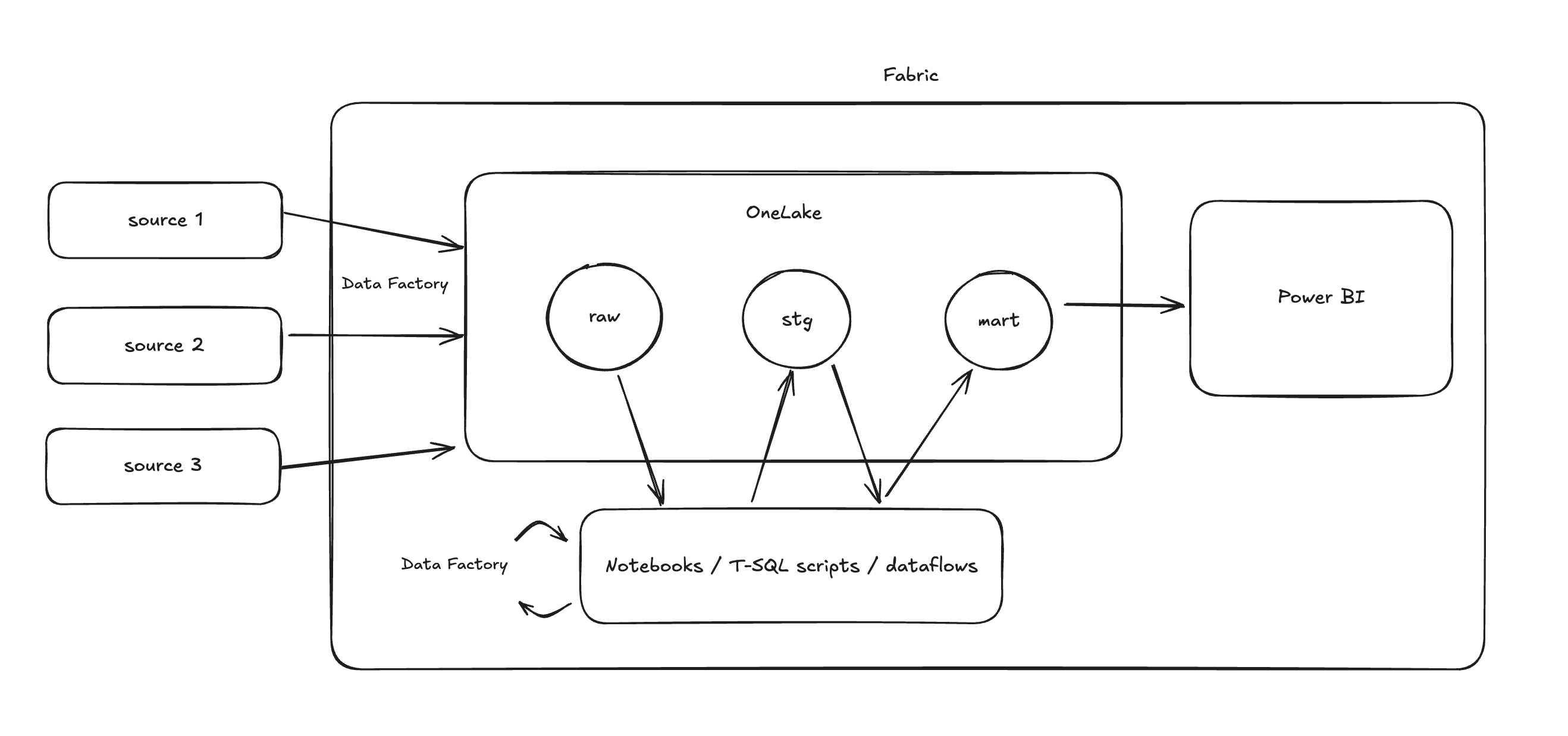
An example workflow for a typical ETL/ELT project might be something like this:
Use Data Factory to ingest data from your source into OneLake (EL)
Apply data transformations (T)
Use Spark in notebooks that read from and write to “Fabric Lakehouse”
Use T-SQL scripts to do transformation with “Fabric Warehouse“
Or mix of both approaches
Orchestrate data ingestion and transformation jobs in Spark notebooks or SQL scripts with Data Factory (orchestration). Or you could schedule to run notebooks without using Data Factory.
Build Power BI reports on top of the SQL end-points in either Fabric lakehouse or warehouse
Benefits and Challenges
Let’s list out some of Fabric’s benefits and challenges.
Benefits
All-in-one SaaS platform. You do not need to care about the underlying infrastructure. Once you start using Fabric, you can do a lot from data engineering and analytics to data science.
Fabric is an expansion of Power BI Premium. If your org already has Power BI Premium capacity then you automatically get Fabric, which provides you a smooth transition to get started with a full-featured data platform.
There are unique features that are only available through Fabric such as:
DirectLake. It enables near real-time reporting in Power BI with the speed of the import mode (data cached in Power BI). You know how this can be a game changer if you know how slow the direct query mode in Power BI is.
OneLake is a neat concept that doesn’t require you to copy data every time but you just reference them in one place.
Needless to say that you can utilize table formats like Delta lake.
Microsoft also recently introduced something called “Python Notebooks“ where you don’t have to use Spark and it uses a single node cluster by default which could be efficient from both the cost and efficiency standpoint. You can use tools like DuckDB and Polars for handling data processing.
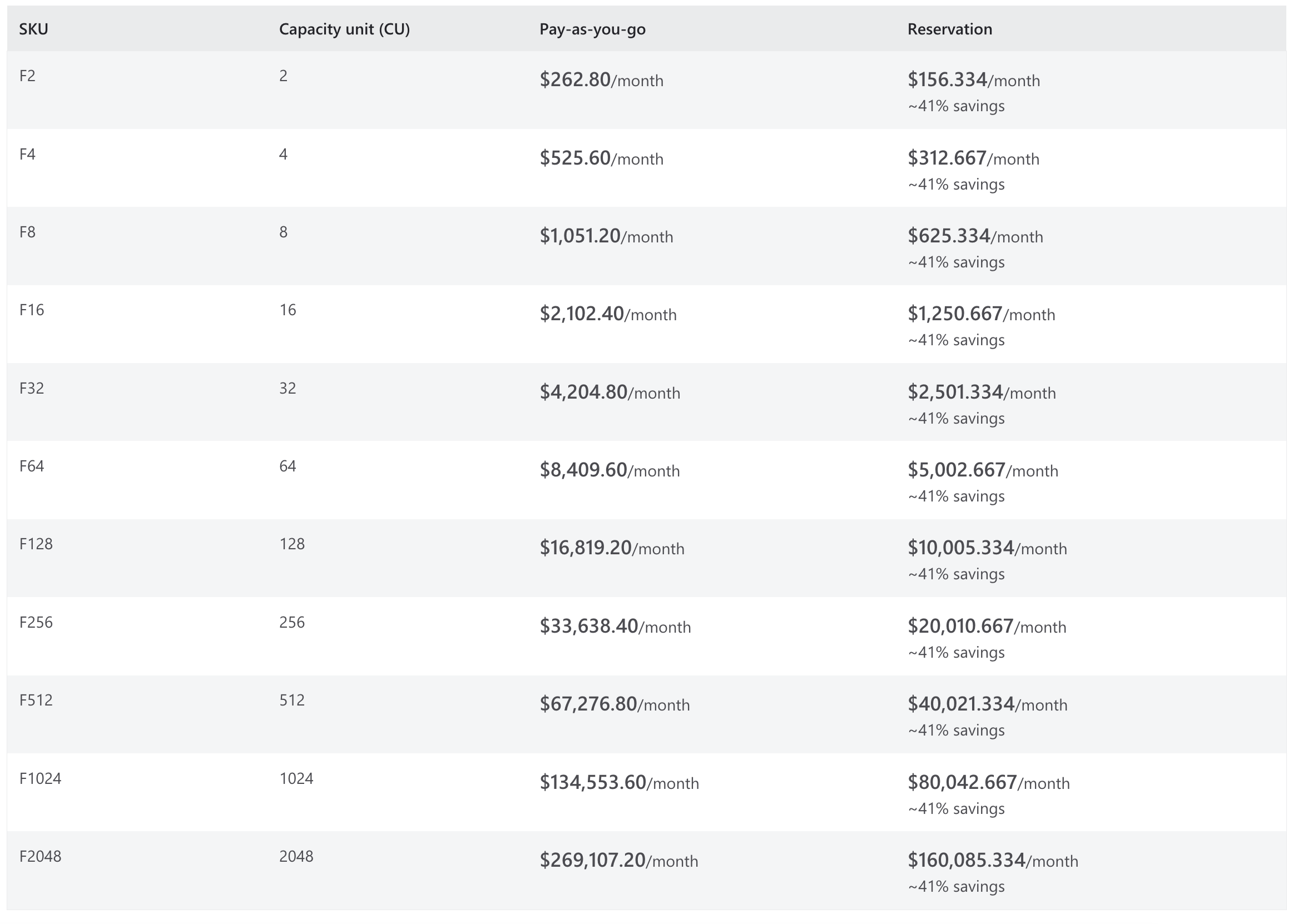
Fabric offers 2 different pricing options. Pay-as-you-go and Reservation. Their Pay-as-you-go is not a typical Pay-as-you-go model though. You still pay a fixed cost but it gives you the ability to switch your SKU depending on your need and workload. With Reservation, you get discounts but you’ll have to keep a SKU for a certain period of time. Pricing wise, you can start with as low as a few hundred dollars a month. However, if you’re using Fabric at enterprise scale then it’ll probably something like F64 and above.
Challenges
There is no true pay-as-you-go pricing option that other vendors like Databricks and Snowflake offer. With Fabric, you have to pay first to get your capacity. If your utilization is lower than the capacity you bought, you still pay the full price. Where other vendors allow you to pay less when you use less and pay more when you use more.
Because of the pricing/capacity model Fabric employs, it’s hard to see what workload is costing how much capacity. Nonetheless, Fabric provides you a way to dig into your capacity usage.
Understanding Fabric’s overall architecture is not easy. Or at least it’ll get some time to get used to the whole Microsoft ecosystem especially if you’re coming from non-Microsoft background. There are many components and ways to leverage each. There are many ways to organize them and it can be a mess. Especially if you’re using Fabric at a large-enterprise setting, the immaturity of the product might become evident.
Immature CI/CD processes. You’ll likely be using Azure DevOps (Repo and Build/Release Pipelines) with Fabric Git Integration + Deployment Pipelines. And it works until it doesn’t. It seems there are so many options you can do this and it can confuse the users. I’ve only done this with Power BI to a certain extent, but a few folks I’ve talked to who are using Fabric in production said the CI/CD feature can still be buggy and there is lots of room for improvement. Just fyi, there is a Python library recently released that helps with CI/CD in Fabric, which seems like a great add. Also, this article gives you a general sense of what your CI/CD workflow will look like in Fabric.
Best Practices for Implementation
Microsoft pushes for a medallion architecture. It is a concept that Databricks rebranded.

You basically build a Fabric Lakehouse/Warehouse for each zone. And use something like Notebooks to define transformations.
But even then, there are so many ways you can implement Fabric. Especially, whether to use Fabric Lakehouse vs Fabric Warehouse. The below screenshot shows how you might want to choose which one to use.

I personally opt to use Fabric Lakehouse to keep it simple. It gives you more options and flexibility. Unless you’re using something like dbt that only works with Fabric Warehouse. Not sure how mature the dbt integration is with Fabric though.
Also, there has been discussions around how you should be using Fabric workspaces for each environment (DEV, UAT, PROD) and layer (bronze, silver, gold). In general, I suggest creating a workspace per environment:

I don’t think anyone wants to end up like this workspace sprawl:

These 2 screenshots are from this article, which dives into this issue in detail which you might find helpful.
For CI/CD stuff, try the Git integration feature in Fabric. It syncs Fabric items (Lakehouse, Warehouse, Notebooks, Power BI models) with what’s in a Git repo (Azure DevOps/GitHub). If you’re already using Fabric and not haven’t tried it yet, it might be worth looking into.
One other piece of advice I’d give is to use Python Notebooks. Most of the workloads are probably not handling big data, and these days tools like DuckDB and Polars can go a long way.
Future Outlook and Development
Fabric definitely needs to mature in many aspects as a product before it can compete other vendors like Databricks.
Also, there has been voices saying there should be “Fabric Per User“ licensing option. For those who don’t know, in Power BI, there is the “Power BI Premium Per User“ license. Meaning you get to use pretty much all the premium features without buying what we call a Power BI capacity, which would cost $4~5k/month to start. But with a Premium Per User license, you get it at like $20/month/user.
Another thing to note is that dbt can work with Fabric, but only with Fabric Warehouse. I don’t know many places that use dbt with Microsoft data tools, but I’m looking forward to seeing further development, maturity, and user adoption of this integration (along with SQLMesh’s integration, if that ever happens).
Conclusion
When I talked with folks who are satisfied with Fabric in production are those who were already using Power BI Premium and didn’t have a solid data engineering infrastructure. So, going with Fabric already meant a good stretch for their organization that expanded their data analytics capability as a whole.
On the other hand, I’ve also heard about stories where the management of some companies decided to use Fabric even though they already have a good working data infra on Databricks and whatnot.
I can’t say for sure since each use case is different, but for organizations without a solid data infrastructure that already use Power BI, Fabric might be worth exploring. However, if you already have a well-functioning data infrastructure and are considering switching to Fabric, it would be wise to carefully weigh the pros and cons before making the move.
All in all, I’m excited to see where Fabric goes over the next 5 years down the road. Microsoft is pushing Fabric like crazy, so maybe it catches up to where Databricks is in a few years. Or it could remain an underdeveloped product. Who knows. What I know is Microsoft will keep pushing Fabric so if your company will likely be using Fabric then you’d better start learning now.
Let me know what thoughts you have on Fabric!
Thanks for sharing you have summarized everything we need to know to start with fabric :)
Very good job presenting the basic concepts